
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 머신러닝
- 대학원
- 파이썬
- 공공데이터
- 데이터 분석
- 데이터사이언티스트
- 코딩테스트
- 이력서 첨삭
- 주요 파라미터
- 데이터분석
- 퀀트
- 커리어전환
- 판다스
- 하이퍼 파라미터
- 주가데이터
- 퀀트 투자 책
- 하이퍼 파라미터 튜닝
- 과제전형
- 데이터 사이언티스트
- 데이터사이언스
- 랜덤포레스트
- 데이터 사이언스
- 경력기술서 첨삭
- pandas
- 사이킷런
- AutoML
- 자기소개서
- 주식데이터
- 경력 기술서
- sklearn
- Today
- Total
GIL's LAB
k-최근접 이웃의 k값 튜닝 방법 본문
이번 포스팅에서는 k-최근접 이웃의 k값을 튜닝하는 방법에 대해 알아보겠습니다.
포스팅을 업데이트하면서 다양한 rule of thumbs를 검증해보겠습니다.
데이터
데이터는 모두 KEEL에서 수집했으며, 수집한 데이터는 다음과 같습니다.
분류
분류 데이터로는 아래와 같은 총 104개의 데이터셋을 활용했습니다.
abalone, abalone19, abalone9-18, adult, australian, balance, banana, bands, breast, bupa, car, census, chess, cleveland, coil2000, connect-4, contraceptive, crx, dermatology, ecoli-0-1-3-7_vs_2-6, ecoli-0_vs_1, ecoli, ecoli1, ecoli2, ecoli3, ecoli4, fars, flare, german, glass-0-1-2-3_vs_4-5-6, glass-0-1-6_vs_2, glass-0-1-6_vs_5, glass, glass0, glass1, glass2, glass4, glass5, glass6, haberman, heart, housevotes, ionosphere, kddcup, kr-vs-k, led7digit, letter, magic, mammographic, marketing, monk-2, movement_libras, mushroom, new-thyroid1, newthyroid, nursery, optdigits, page-blocks-1-3_vs_4, page-blocks, page-blocks0, penbased, phoneme, pima, poker, ring, saheart, satimage, segment, segment0, shuttle-c0-vs-c4, shuttle, sonar, spambase, spectfheart, splice, texture, thyroid, tic-tac-toe, titanic, twonorm, vehicle, vehicle0, vehicle1, vehicle2, vehicle3, vowel, vowel0, wdbc, wine, winequality-red, winequality-white, wisconsin, yeast-0-5-6-7-9_vs_4, yeast-1-2-8-9_vs_7, yeast-1-4-5-8_vs_7, yeast-1_vs_7, yeast-2_vs_4, yeast-2_vs_8, yeast, yeast1, yeast3, yeast4, yeast5, yeast6회귀
회귀 데이터로는 아래와 같은 총 31개의 데이터셋을 활용했습니다.
abalone, ailerons, ANACALT, autoMPG6, autoMPG8, baseball, california, compactiv, concrete, dee, delta_ail, delta_elv, ele-1, ele-2, elevators, forestFires, friedman, house, laser, machineCPU, mortgage, mv, plastic, pole, puma32h, quake, stock, tic, treasury, wankara, wizmir
데이터 준비
k를 1부터 50까지 바꿔가면서 정확도(분류)와 MAE(회귀)를 측정했습니다. 이렇게 측정한 데이터 구조는 아래와 같습니다.
분류

회귀

k값에 따른 성능 분포
데이터별로 score의 순위를 계산합니다. 정확도는 클수록 1에 가까운 순위를 부여했으며, MAE는 작을수록 1에 가까운 순위를 부여했습니다.
그리고 데이터별 순위 평균을 구해서 x축은 k값, y축은 순위가 되도록 시각화했습니다.
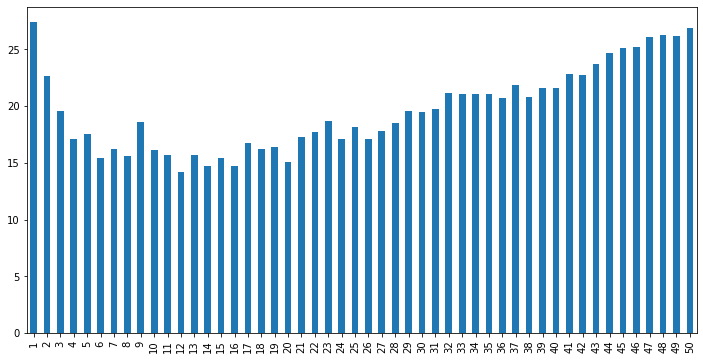
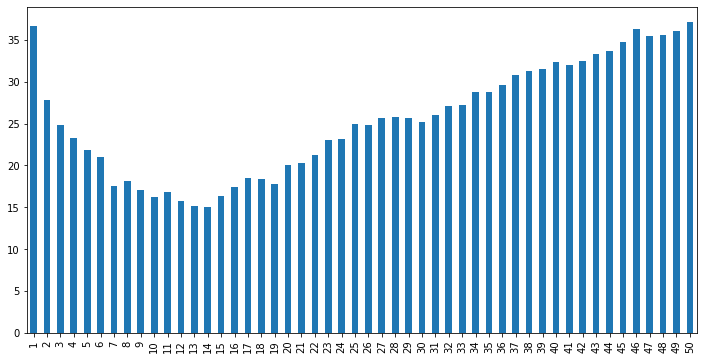
그 결과, 두 과제 모두 아래로 볼록한 형태인 분포로 나왔으며, k가 5 ~ 20일때 평균적으로 좋은 순위를 얻음을 확인했습니다.
분류
회귀
Rule of Thumbs 검증
k = 1부터 50까지의 점수를 평균낸 것과 rule of thumbs로 설정한 k의 점수를 비교할 것입니다.
다만 데이터에 따라 점수의 스케일 차이가 많이 나므로 각 값을 최댓값으로 나눠주겠습니다.
예를 들어, k = 1부터 50까지의 평균 MAE가 10이고 rule of thumbs로 설정한 k의 MAE가 20이라면, 각 점수는 10/20과 20/20으로 변환합니다.
sqrt(n)
k를 샘플 수에 루트를 취한 값으로 설정하는 것이 좋다는 rule of thumbs입니다.
샘플이 만 개만 되도 k가 100이 되서 너무 큰 거 아닐까 싶긴한데, 혹시 모르니 검증해보도록 하겠습니다.
분류
회귀 모델에서 sqrt(n)과 average를 비교한 결과는 아래와 같습니다. 참고로 막대가 높을수록 좋은 결과입니다.

데이터가 너무 많아서 무슨 막대가 더 위에 많이 있는지 알기 어렵습니다.
평균이 sqrt(n)보다 높은 케이스는 총 58.65%로, 1부터 50사이에 아무 값이나 쓰는 것이 sqrt(n)을 쓰는 것보단 좋다고 할 수 있습니다.
회귀
회귀 모델에서 sqrt(n)과 average를 비교한 결과는 아래와 같습니다. 참고로 막대가 높을수록 좋지 못한 결과입니다.

주황색이 더 값이 작은 경우(예: baseball)도 있지만 대다수는 평균에 못미칩니다.
정확히는 67.74%가 평균에 못미칩니다.
결론적으로 sqrt(n)으로 설정하는 것은 1 ~ 50 사이에서 임의로 설정하는 것과 크게 차이가 없거나, 더 안 좋은 방법이라고 할 수 있습니다.

하이퍼 파라미터 튜닝 실험에 관한 질문이나 추가 실험 요청 사항이 있으시면 댓글이나 이메일(gils_lab@naver.com)을 남겨주시기 바랍니다.
해당 포스팅이 도움되었다면 공감 버튼 클릭부탁드립니다!
출처: https://gils-lab.tistory.com/90 [GIL's LAB:티스토리]
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| 변수 구간화(범주화) (0) | 2023.03.06 |
|---|---|
| 회귀 모델 성능 비교 (0) | 2022.12.21 |
| 서포트 벡터 머신(이진 분류, rbf 커널)의 하이퍼 파라미터 튜닝 (0) | 2022.07.29 |
| 랜덤 포레스트(회귀)의 하이퍼 파라미터 튜닝 (0) | 2022.07.28 |
| 랜덤 포레스트(이진 분류)의 하이퍼 파라미터 튜닝 (0) | 2022.07.25 |



