
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 경력기술서 첨삭
- 데이터사이언스
- 퀀트 투자 책
- 자기소개서
- 커리어전환
- 데이터사이언티스트
- 사이킷런
- 대학원
- 하이퍼 파라미터
- AutoML
- 데이터사이언스학과
- 주요 파라미터
- 코딩테스트
- sklearn
- 퀀트
- 파이썬
- 머신러닝
- 주식데이터
- 데이터 사이언스
- 과제전형
- 하이퍼 파라미터 튜닝
- 판다스
- 랜덤포레스트
- 주가데이터
- 이력서 첨삭
- 데이터 분석
- pandas
- 데이터분석
- 경력 기술서
- 데이터 사이언티스트
- Today
- Total
GIL's LAB
변수 구간화(범주화) 본문
오랜만에 포스팅입니다.
본 포스팅에서는 변수를 구간화하는 방법에 대해 알아보겠습니다.
변수 구간화란?
변수 구간화는 연속형 변수를 정해진 구간에 따라 구간화하여 서열형 변수로 변환하는 작업이라 할 수 있습니다.
간단한 예시를 살펴보겠습니다.

위 예시에서는 신장(cm)이란 변수를 세 개의 구간으로 구간화했습니다. 즉, 신장이 180cm이던 A란 사람은 [180, 190)의 구간에 속하므로 신장이 3으로 변했고, 신장이 175인 D란 사람은 [170, 180)이란 구간에 속하므로 2로 변했습니다.
구간화의 효과
그럼 왜 구간화를 하는지에 대해 생각해보겠습니다.
어떤 전처리 기법 혹은 모델링 기법을 사용할 때, 이게 왜 필요한지, 그리고 장/단점은 무엇인지 생각해야 합니다.
구간화를 한다는 것은 연속형 변수를 서열형 변수로 변환하는 것이라 했습니다.
다시 말해, 상태 공간의 크기가 큰 연속형 변수를 상태 공간의 크기가 작은 변수로 변환하는 것입니다.
위 예제에서는 원래 상태 공간이 {155, 165, 170, 175, 180, 185}이었지만, 변환된 상태 공간은 {1, 2, 3}으로 줄었습니다.
샘플이 7개밖에 되지 않아 효과가 와닿지는 않을 수 있지만, 실제 데이터에서는 엄청난 효과가 됩니다.
그러면 상태 공간의 크기가 작을 때의 장점이 무엇인지를 생각하면 됩니다.
메모리 관리 측면에서도 수월하겠지만, 엔지니어링 측면은 무시하고 분석 측면만 생각해보겠습니다.
가장 큰 장점은 사람이 데이터를 이해하기가 더 수월하다는 것입니다.
고등학생때 수능이나 모의고사를 보면 과목별로 원점수, 표준점수 등이 나오지만, 그것보다 직관적으로 받아들이기 쉬운 값이 등급입니다.
그래서 데이터를 모니터링하는 상황 등에서 데이터를 구간화하면 데이터를 빠르게 이해할 수 있습니다.
두 번째 장점은 격자 테이블(cross table)을 만들 수 있다는 것입니다.
즉, 다른 변수와 관계 등을 볼 때, 연속형 변수는 상관관계 등의 수치, 혹은 그래프로 표현하는 것이 최선이지만, 서열형 변수 혹은 범주형 변수는 아래 구조와 같은 그리드를 만들어 그 분포를 쉽게 확인할 수 있습니다.

이번에는 머신러닝(지도학습) 성능 측면에서 생각해보겠습니다.
모델 학습의 속도가 빨라지는 것은 자명하겠지만, 정확도 측면에서는 어떨까요?
당연히 데이터에 따라 그 결과가 다를 것입니다.
결정 나무를 예로 들어보죠.
만약 어떤 라벨을 예측하는데 특정한 연속형 변수가 매우 중요한 역할을 한다고 해보겠습니다.
그러면 그 연속형 변수를 기준으로 노드가 계속해서 분지해나가겠죠. 이렇게 학습한 모델을 A라고 해보겠습니다.
한편, 해당 연속형 변수를 구간화한뒤 모델을 학습해보겠습니다.
그러면 그 변수가 갖는 상태 공간이 줄어들어서 해당 변수를 기준으로 분지할 수 있는 횟수가 크게 줄어들 것입니다.
이렇게 학습한 모델을 B라고 해보겠습니다.
A와 B의 성능 가운데 어느게 더 좋을지는 해보기전까지 사실 알 수 없습니다.
그렇지만 A는 다양한 변수의 효과를 보지 못하고 특정 변수를 기준으로 분지를 많이 하다보니 과적합될 위험이 있습니다. 즉, 해당 변수의 값에 따라 지나치게 민감하게 반응하는 것입니다.
B는 상대적으로 그럴 위험이 적죠.
그렇지만 그렇다고해서 B가 좋다는 보장은 없습니다. 왜냐하면 구간화를 적절하게 하지 못했을 때 발생하는 부작용이 훨씬 더 크기 때문입니다. 게다가 적절히 구간을 나눴다하더라도 원래 데이터가 갖고 있던 정보를 소실하는 문제도 있습니다.
구간화 방법 1. 등간격 구간화
가장 단순한 구간화 방법으로 연속형 변수의 상태 공간을 등간격으로 쪼개는 방법입니다.
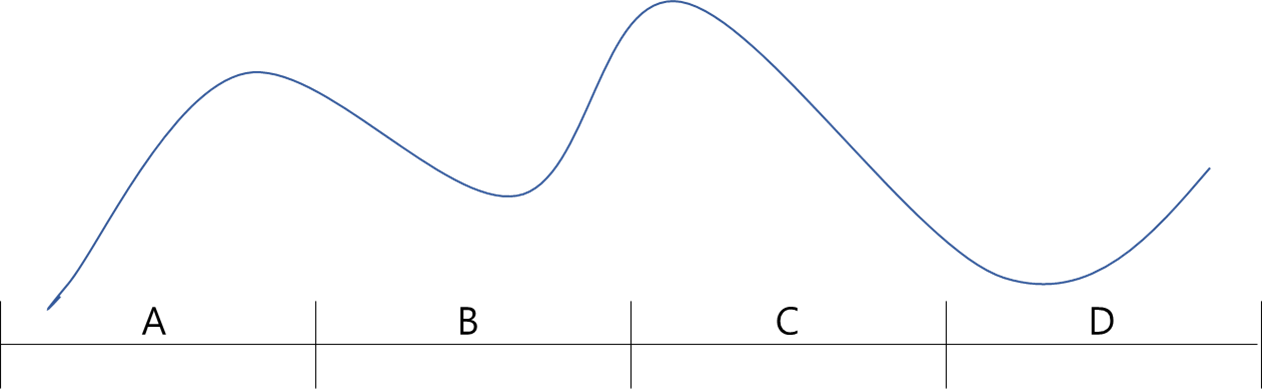
즉, 위의 상태 공간에서 일정한 간격으로 A, B, C, D란 구간을 정의했습니다.
구간화 방법 2. 등빈도 구간화
등빈도 구간화는 각 구간의 빈도가 일정하도록 상태 공간을 쪼개는 방법입니다.
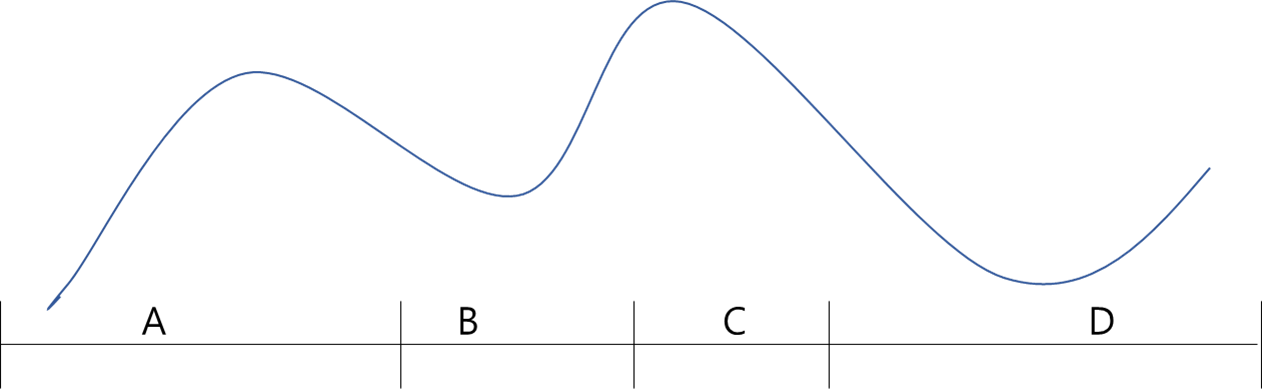
제가 눈으로만 대충 짤랐기 때문에 등빈도처럼 안보일 수 있지만, 각 구간에 속하는 데이터의 비율이 25%씩으로 일정합니다.
구간화 방법 3. 밀도 기반 구간화
각 구간의 밀도에 기반하여 구간화를 하는 방법입니다.
즉, 밀도가 높은 부분을 중심으로 해서 데이터를 구간화하는 것으로 그 구조는 1차원 군집화와 완벽하게 같습니다.
이 부분은 추후 관련 연구 등을 정리해서 올려보겠습니다.
예제
데이터 준비
예제에서는 제가 임의로 만든 신장 데이터를 활용하겠습니다. 아래 데이터를 다운로드받으시면 됩니다.
데이터는 다음과 같이 로드합니다.
import pandas as pd
df = pd.read_excel("구간화_예시데이터.xlsx")
df['신장'].head()[실행 결과]
0 180.86
1 176.07
2 158.82
3 166.06
4 189.48
Name: 신장, dtype: float64
등간격 구간화
등간격 구간화는 판다스의 cut 함수를 사용하면 됩니다.
이 함수의 인자는 x와 bins이 있으며, x는 데이터, bins은 빈의 개수를 의미합니다.
신장 변수를 5개의 구간으로 쪼개보겠습니다.
df['신장_등간격구간'] = pd.cut(df['신장'], 5)
df['신장_등간격구간'][실행 결과]
0 (173.294, 182.872]
1 (173.294, 182.872]
2 (154.138, 163.716]
3 (163.716, 173.294]
4 (182.872, 192.45]
...
95 (163.716, 173.294]
96 (173.294, 182.872]
97 (163.716, 173.294]
98 (154.138, 163.716]
99 (163.716, 173.294]
Name: 신장_등간격구간, Length: 100, dtype: category
Categories (5, interval[float64]): [(144.512, 154.138] < (154.138, 163.716] < (163.716, 173.294] < (173.294, 182.872] < (182.872, 192.45]]위 결과에서 보듯이 (144.512, 154.138], ...., (182.872, 192.45]이라는 다섯개의 구간으로 쪼개졌습니다.
그리고 각 구간의 크기는 154.138 - 144.512, ..., 192.45 - 182.872로 서로 비슷합니다.
참고로 이렇게 만들어진 판다스의 시리즈 타입을 카테고리라 하며, 자세한 설명은 생략하겠습니다.
등빈도 구간화
등빈도 구간화는 판다스의 qcut 함수를 사용하면 됩니다.
이 함수의 인자는 x와 bins이 있으며, x는 데이터, bins은 빈의 개수를 의미합니다.
신장 변수를 5개의 구간으로 쪼개보겠습니다.
df['신장_등빈도구간'] = pd.qcut(df['신장'], 5)
df['신장_등빈도구간'][실행 결과]
0 (179.072, 192.45]
1 (173.522, 179.072]
2 (144.559, 163.754]
3 (163.754, 168.744]
4 (179.072, 192.45]
...
95 (168.744, 173.522]
96 (179.072, 192.45]
97 (163.754, 168.744]
98 (144.559, 163.754]
99 (163.754, 168.744]
Name: 신장_등빈도구간, Length: 100, dtype: category
Categories (5, interval[float64]): [(144.559, 163.754] < (163.754, 168.744] < (168.744, 173.522] < (173.522, 179.072] < (179.072, 192.45]]이번에는 각 구간의 크기가 다름을 알 수 있습니다.
value_counts 메서드를 이용해 각 구간에 속하는 샘플의 비율을 확인해보겠습니다.
df['신장_등빈도구간'].value_counts()[실행 결과]
(144.559, 163.754] 20
(163.754, 168.744] 20
(168.744, 173.522] 20
(173.522, 179.072] 20
(179.072, 192.45] 20
Name: 신장_등빈도구간, dtype: int64실행 결과에서 보듯이, 각 구간에 20개의 샘플이 동일하게 들어갔음을 알 수 있습니다.
단, 데이터 개수와 분포에 따라 완벽한 등빈도는 나오지 않을 수 있습니다.
데이터 분석 서비스가 필요한 분은 아래 링크로!
데이터사이언스 박사의 데이터 분석 서비스 드립니다. | 150000원부터 시작 가능한 총 평점 5점의 I
78개 총 작업 개수 완료한 총 평점 5점인 데이터사이언스박사의 IT·프로그래밍, 데이터 분석·시각화 서비스를 68개의 리뷰와 함께 확인해 보세요. IT·프로그래밍, 데이터 분석·시각화 제공 등 150
kmong.com
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| 영어 감성 사전 (0) | 2023.08.08 |
|---|---|
| 회귀 모델 성능 비교 (0) | 2022.12.21 |
| k-최근접 이웃의 k값 튜닝 방법 (0) | 2022.07.31 |
| 서포트 벡터 머신(이진 분류, rbf 커널)의 하이퍼 파라미터 튜닝 (0) | 2022.07.29 |
| 랜덤 포레스트(회귀)의 하이퍼 파라미터 튜닝 (0) | 2022.07.28 |


