
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 경력 기술서
- 코딩테스트
- 경력기술서 첨삭
- 커리어전환
- 랜덤포레스트
- 하이퍼 파라미터
- 과제전형
- 데이터 분석
- 머신러닝
- 하이퍼 파라미터 튜닝
- 데이터사이언스
- 데이터사이언티스트
- 주식데이터
- 자기소개서
- 판다스
- 대학원
- 퀀트
- 이력서 첨삭
- 파이썬
- sklearn
- pandas
- 퀀트 투자 책
- 주요 파라미터
- 주가데이터
- 공공데이터
- 데이터분석
- 사이킷런
- 데이터 사이언티스트
- AutoML
- 데이터 사이언스
- Today
- Total
GIL's LAB
서포트 벡터 머신(이진 분류, rbf 커널)의 하이퍼 파라미터 튜닝 본문
이번 포스팅에서는 이진 분류를 위한 서포트 벡터 머신(SVM)의 하이퍼 파라미터를 튜닝하는 방법에 대해 알아보겠습니다.
커널까지 비교하려하다보니 시간이 너무 오래 걸릴 것 같아, rbf 커널을 갖는 SVM으로 한정했습니다.
SVM은 sklearn.svm.SVC를 이용해서 구현하겠습니다.
하이퍼 파라미터
sklearn.svm.SVC의 주요 하이퍼 파라미터(함수 인자)는 다음과 같습니다.
하이퍼 파라미터에 대한 설명은 scikit learn의 공식 문서를 참고해서 작성했습니다.
- C: 정규화 파라미터로, 이 값이 클수록 정규화 강도가 약합니다. L2 페널티이며, 기본값은 1입니다.
- kernel: 커널을 결정하며,'linear' (선형), 'poly' (다항), 'rbf', 'sigmoid' (시그모이드) 중 하나로 선택합니다. 이 포스팅에서는 'rbf'로 고정했습니다. 각 커널 함수는 아래와 같습니다.

- gamma: RBF, 다항, 시그모이드 커널에 포함된 하이퍼 파라미터인 감마입니다.
- degree: 다항 커널에 포함된 하이퍼 파라미터인 d입니다.
- coef0: 다항 커널과 시그모이드 커널에 포함된 세타입니다.
- tol: Tolerance for stopping criterion로 학습 이터레이션이 진행될 때 이 수치 미만으로 목적 함수가 갱신되는 경우 학습이 종료됨
실험 데이터
실험에 사용할 데이터는 KEEL에서 수집했으며, 수집한 데이터 목록은 다음과 같습니다.
- bands
- bupa
- chess
- crx
- ecoli-0_vs_1
- glass0
- glass1
- heart
- housevotes
- ionosphere
- iris0
- mammographic
- monk-2
- pima
- saheart
- sonar
- spambase
- tic-tac-toe
- titanic
- wdbc
- wisconsin
실험 방법
각 데이터마다 아래와 같은 범위에서 그리드 서치를 수행합니다.
- C: 10^(-2), 10^(-1), ..., 10^6
- tol: 10^(-6), 10^(-5), ..., 10^(-1)
- gamma: 10^(-7), 10^(-6), ..., 10^(3)
즉, 각 데이터마다 594(=9*6*11)개의 하이퍼 파라미터 조합을 평가합니다.
이렇게 측정한 데이터를 바탕으로 주요 하이퍼 파라미터와 그 범위를 식별하겠습니다.
실험 결과
데이터에 따른 성능 범위
데이터에 따른 성능 범위(최댓값 - 최솟값)는 다음과 같습니다.
거의 1에 가까운 데이터(housevotes, mammographic)도 있고, 0.2보다 작은 데이터(iris0, chess)도 있는 것을 알 수 있습니다.

이처럼 서포트 벡터 머신은 하이퍼 파라미터 세팅에 매우 민감하다고 할 수 있습니다. 심지어 같은 커널인데도 말이죠.
C에 따른 성능 분포
C에 따른 F1 score의 분포는 다음과 같습니다. 참고로 x축에 있는 값은 C가 아니라, logC를 나타냅니다. 즉, C가 10^(-2), 10^(-1), ...., 10^(6)일 때의 성능입니다.
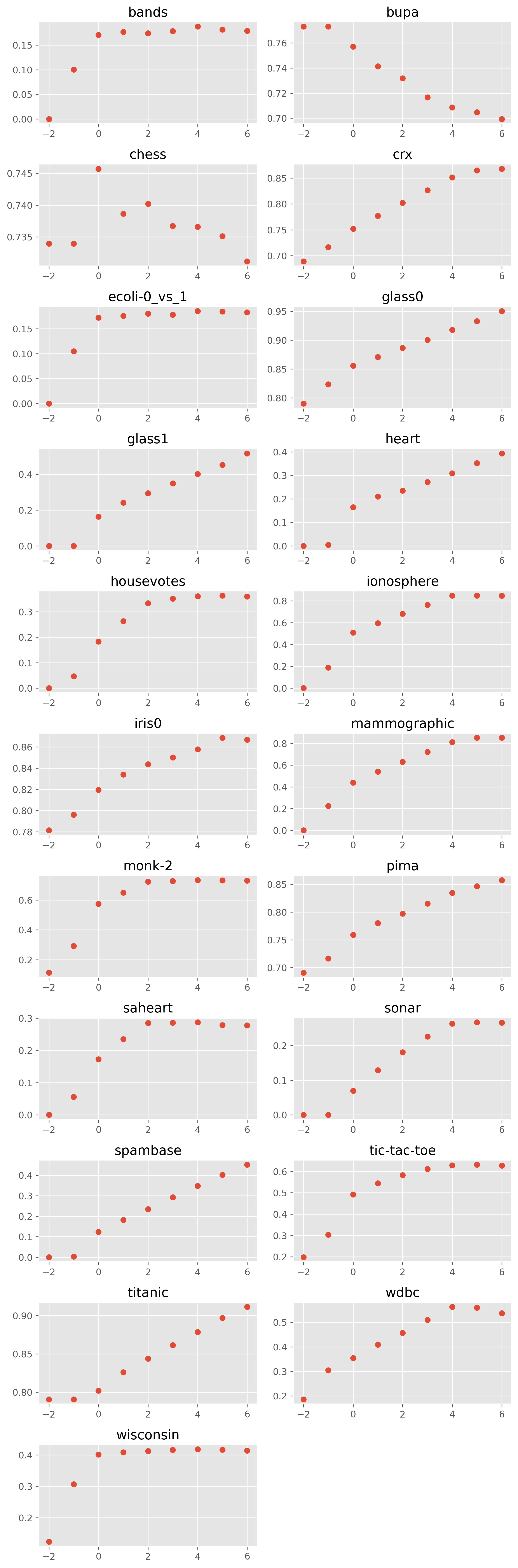
굉장히 재미있는 양상으로, 실험 결과를 세 가지 케이스로 구분할 수 있습니다.
(1) C가 커질수록 성능이 증가하거나, 증가하다 수렴함 (예: titanic, wisconsin). C는 복잡도 파라미터이므로, 만약 더 많은 C를 튜닝했으면 대부분이 결국 수렴하지 않을까 예상할 수 있습니다
(2) C가 커질수록 성능이 감소함 (예: bupa)
(3) C와 성능은 무관함 (예: chess)
일단 대다수 데이터가 C와 성능이 정비례했습니다.
그러므로 C를 가능한 큰 범위에서 튜닝하는 것이 유리하다고 할 수 있습니다.
그러나 C가 커질수록 성능이 감소하기도 합니다.
두 경우 모두 극단에서 성능이 좋고, 또 기본값인 0에서도 성능이 좋은 편입니다.
따라서 다음과 같은 튜닝 범위를 추천할 수 있습니다.
C: {10^(-2), 10^(0), 10^(5), 10^(7)}
Gamma에 따른 성능 분포
gamma에 따른 성능 분포는 다음과 같습니다.
C와 마찬가지로 x축은 log(gamma)라고 보시면 됩니다.
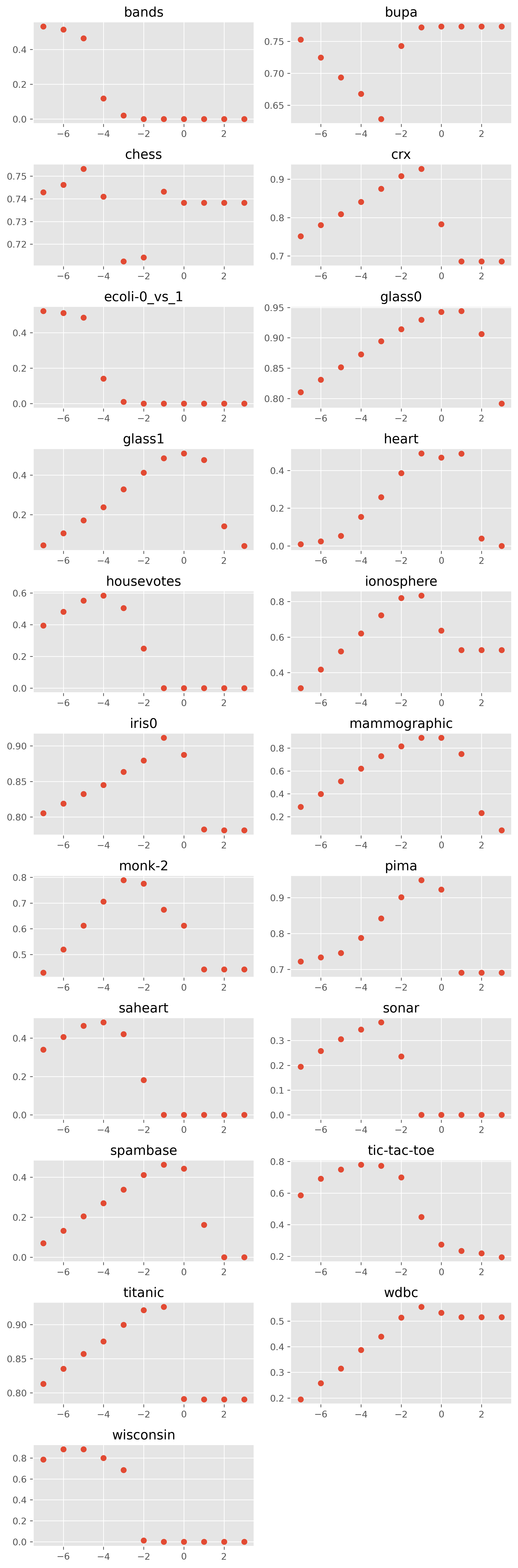
대다수 데이터에 대해서 증가하다가 감소하고 수렴합니다.
가장 대표적인 그림이 tic-tac-toe 데이터 같습니다.
그런데 band와 bupa는 다른 데이터랑 다르게 감소하다 증가합니다.
변동이 매우 크므로 gamma는 반드시 튜닝해야 합니다.
데이터의 특성에 따라 차이가 너무 커서 현재 탐색한 범위를 일부 수정하는 것이 가장 현실적일 것 같습니다.
gamma: {10^(-7), 10^(-6), 10^(-5), 10^(-1), 10^(0), 10^(1)}
tol에 따른 성능 분포
tol에 따른 성능 분포는 그래프로 보는 것이 의미가 없을 정도로 차이가 작습니다.
대신에 tol에 따른 F1 score의 최댓값에서 최솟값을 뺀 결과를 보도록 하겠습니다.
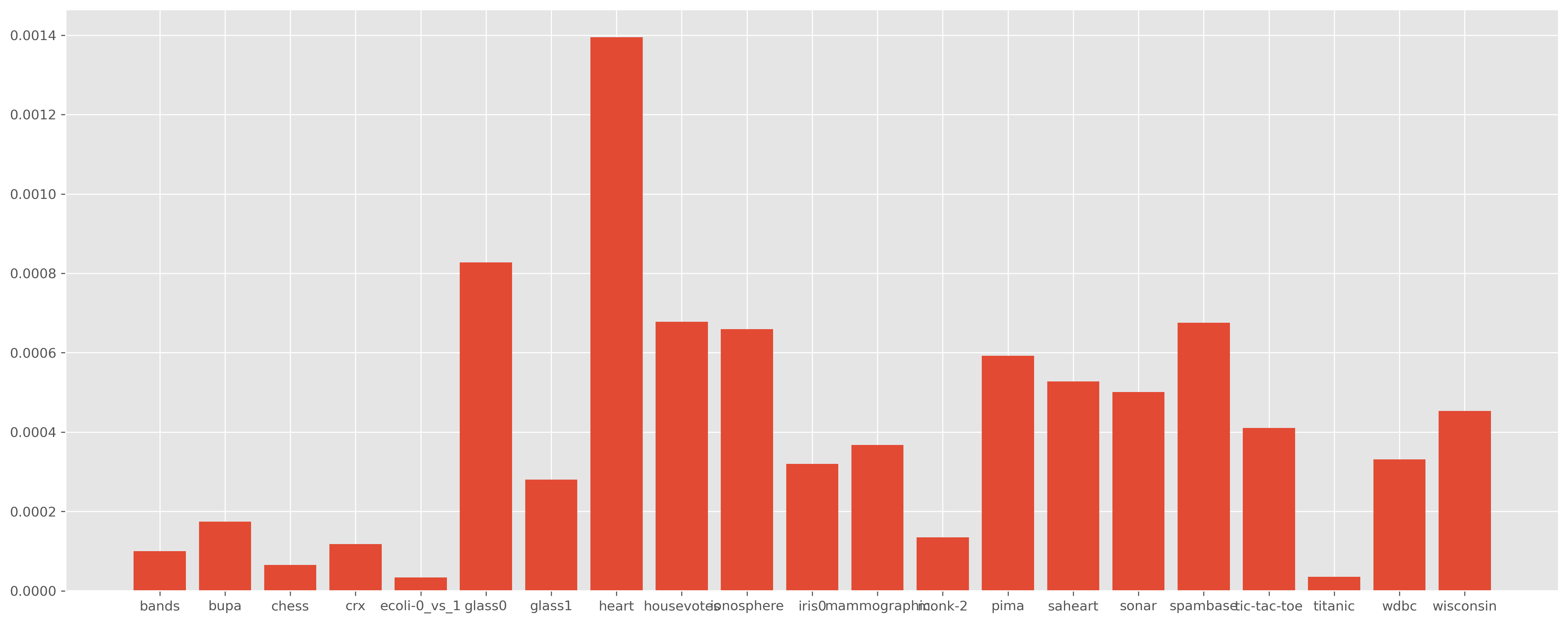
제법 차이가 나는데?라고 생각하셨다면, 그래프를 볼 때 꼼꼼히 보라고 말씀드리고 싶습니다.
y축의 범위를 보면 0.0000 ~ 0.0014입니다.
즉, tol을 튜닝해서 얻을 수 있는 성능 향상은 최대 0.0014에 불과하며, 대다수는 0.001도 향상시킬 수 없습니다.
따라서 최소한 현재 범위에서 tol은 튜닝할 필요가 없다고 할 수 있습니다.
(C, Gamma)에 따른 성능 분포
마지막으로 C와 gamma의 조합에 따른 성능을 보겠습니다.

색이 환할수록 좋다고 할 수 있습니다. 데이터에 따른 편차가 있긴 하지만, 주로 C가 크고 gamma는 작을 때 좋은 결과를 낸다고 할 수 있습니다.
더 정확히는 gamma와 C가 서로 대칭되는 점에 있을 때 좋은 결과를 냅니다.여기서도 bupa만 예외가 있네요.
따라서 C가 10^(k)일 때, gamma는 10^(-k-n)으로 튜닝하는 것이 좋아보입니다 (k = 3, 4, 5, 6; n = 0, 1, 2).

하이퍼 파라미터 튜닝 실험에 관한 질문이나 추가 실험 요청 사항이 있으시면 댓글이나 이메일(gils_lab@naver.com)을 남겨주시기 바랍니다.
해당 포스팅이 도움되었다면 공감 버튼 클릭부탁드립니다!
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| 회귀 모델 성능 비교 (0) | 2022.12.21 |
|---|---|
| k-최근접 이웃의 k값 튜닝 방법 (0) | 2022.07.31 |
| 랜덤 포레스트(회귀)의 하이퍼 파라미터 튜닝 (0) | 2022.07.28 |
| 랜덤 포레스트(이진 분류)의 하이퍼 파라미터 튜닝 (0) | 2022.07.25 |
| 모델별 하이퍼 파라미터 튜닝 가이드라인 (0) | 2022.07.25 |



