
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 랜덤포레스트
- AutoML
- 퀀트 투자 책
- 데이터사이언스
- 퀀트
- 자기소개서
- pandas
- 공공데이터
- 하이퍼 파라미터 튜닝
- 판다스
- 데이터사이언티스트
- 경력 기술서
- 경력기술서 첨삭
- 코딩테스트
- 이력서 첨삭
- sklearn
- 하이퍼 파라미터
- 사이킷런
- 커리어전환
- 데이터 사이언스
- 데이터 사이언티스트
- 머신러닝
- 주요 파라미터
- 파이썬
- 주식데이터
- 데이터 분석
- 과제전형
- 주가데이터
- 데이터분석
- 대학원
- Today
- Total
GIL's LAB
[논문 리뷰] 베이지안 최적화 (Bayesian Optimization) 본문
논문: Frazier, P. I. (2018). A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.
어떤 문제를 다루나?
미지의 목적 함수 f를 최대화하는 최적화 문제
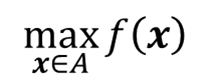
- x: 20차원 이하의 실수 벡터, x = (x_1, x_2, ..., x_n)
- A: feasible set, 통상적으로 hyper-rectangle 형태 (즉, a_i ≤ x_i ≤ b_i)
- 목적 함수 f의 특성
-
continuous
-
black-box: 지금까지의 데이터로 추정해야 함
-
expensive to evaluate: 데이터가 부족함
-
derivative-free: 도함수를 모름 => Newton’s Method, Gradient descent 등 사용 불가
-
noise-free: 측정에서 발생하는 노이즈는 없다고 가정함
-
- 지역 최적해보다 전역 최적해를 찾는 것이 주 목적
베이지안 최적화 개요
아래 그림과 같이 Acquistion function, surrogate model, objective function으로 구성됩니다.



- 이미 테스트한 포인트 근처는 테스트하는데 비용이 많이 들고 노이즈가 없다고 가정했으므로 추가로 테스트하지 않아야 합니다. 따라서 이미 근처를 테스트한 구간은 Acquisition function 값이 0에 가깝습니다.
- 우리가 추정한 곳에서 그나마 값이 큰 구간을 위주로 찾아야 합니다.
가우시안 프로세스 회귀
다변량 정규 분포
가우시안 프로세스는 기본적으로 함숫값들이 다변량 정규 분포를 따른다고 간주합니다.
두 변수 x1과 x2가 다변량 정규 분포를 따른다는 것은 다음과 같이 쓸 수 있습니다.

가우시안 프로세스에서 함수값들이 다변량 정규분포를 따른다고 가정하는데, 여기서 핵심은 각 함수값이 독립적이지 않다는데 있습니다. 즉, 위 수식에서 x1의 분포에 x2가 영향을 끼칩니다. 측정한 함수값이 많아지면 다변량 정규 분포의 차원이 무한대에 가까워질 것이므로, 가우시안 프로세스를 비모수 모델로 볼 수 있습니다.

기본 구조
함수 값은 다변량 정규 분포를 따른다고 가정하며, 함수값 간 관계는 커널로 정의합니다.

여기서 x^(1:n)은 (x^1, x^2, ..., x^n)을 축약해서 쓴 것입니다.
새로운 데이터 x^(n+1)의 함수값 f(x^n)은 다음과 같이 조건부 분포를 이용하여 예측합니다.
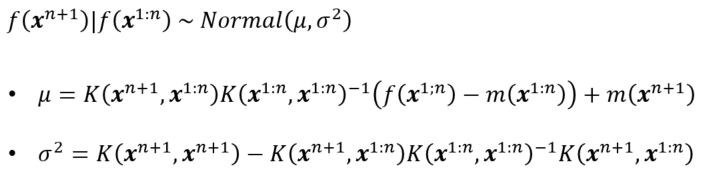
커널 함수

이제 f(x_4)를 예측하는 구조를 살펴보겠습니다.

그 구조가 가중합 꼴입니다. 그리고 x1이 x4와 가장 가까우므로, K(x1, x4)가 가장 크고, 그에 따라 f(x1)이 f(x4) 예측에 가장 큰 영향을 줍니다.
대표적인 평균 함수와 커널 함수
대표적인 커널 함수로는 power exponential (Gaussian) kernel이 있으며, 다음과 같이 생겼습니다.
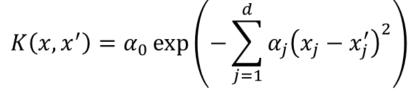
여기서 알파는 커널의 하이퍼파라미터로 최대 가능도 방법으로 추정합니다.
대표적인 평균 함수는 상수함수입니다. 즉, 평균을 상수로 고정해놓고 커널로 튜닝하는 형태를 많이 씁니다.
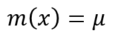
Acqusition function
대표적인 Acqusition function으로는 expected improvement (EI)가 있습니다. EI는 말그대로 새로운 데이터를 측정했을 때 향상되는 함숫값에 대한 기대값입니다.EI를 바탕으로 다음 측정할 데이터 포인트 x^(n+1)은 다음과 같이 찾습니다.

Python packages
https://github.com/fmfn/BayesianOptimization
데이터 분석 서비스가 필요한 분은 아래 링크로!
데이터사이언스 박사의 데이터 분석 서비스 드립니다. | 150000원부터 시작 가능한 총 평점 5점의 I
78개 총 작업 개수 완료한 총 평점 5점인 데이터사이언스박사의 IT·프로그래밍, 데이터 분석·시각화 서비스를 68개의 리뷰와 함께 확인해 보세요. IT·프로그래밍, 데이터 분석·시각화 제공 등 150
kmong.com
'데이터사이언스 > 최적화' 카테고리의 다른 글
| Particle Swarm Optimization, 입자 군집 최적화 (0) | 2022.12.25 |
|---|---|
| 베이지안 최적화 (1) 블랙박스 최적화 문제 (0) | 2022.05.20 |
| 유전 알고리즘을 이용한 특징 선택 (0) | 2022.04.06 |
| 유전 알고리즘 (8) | 2021.10.03 |



