
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 커리어전환
- pandas
- 이력서 첨삭
- 경력기술서 첨삭
- 퀀트
- 데이터사이언티스트
- 주가데이터
- 퀀트 투자 책
- 판다스
- 코딩테스트
- 데이터사이언스
- 주식데이터
- sklearn
- 데이터 사이언티스트
- 과제전형
- 데이터 분석
- AutoML
- 주요 파라미터
- 랜덤포레스트
- 데이터분석
- 경력 기술서
- 머신러닝
- 대학원
- 사이킷런
- 데이터 사이언스
- 공공데이터
- 하이퍼 파라미터 튜닝
- 파이썬
- 하이퍼 파라미터
- 자기소개서
- Today
- Total
GIL's LAB
유전 알고리즘 본문
개요
유전 알고리즘은 자연계의 진화 체계를 모방한 메타휴리스틱 알고리즘으로 복잡한 최적화 문제를 푸는데 사용된다.
스케줄링 등 복잡한 최적화 문제를 해결하는데 활용되고 있고, 딥러닝의 초기 웨이트 설정, 특징 선택 등 머신러닝 문제를 해결하는데도 많이 사용된다.
필자의 주력 연구 방법론중 하나이며, 지금도 유전 알고리즘을 이용한 쉐이플릿 탐색이라는 주제로 연구를 진행하고 있다.
그러면 이제 유전 알고리즘이 어떻게 작동하는지, 또 파이썬으로 어떻게 구현할 수 있는지를 소개하자.
가능하면 비전공자의 입장에서 친절히 설명하고자 한다.
최적화 문제란?
최적화 문제는 제약 하에서 목적식을 최소화 혹은 최대화하는 결정 변수의 값을 찾는 문제이다.
제약이란 것은 해가 만족해야 하는 조건이고, 목적식은 최소화 혹은 최대화해야 하는 대상이며, 결정 변수는 값을 찾아야 하는 변수이다.
위키피디아에서 소개하고 있는 간단한 예제를 보자 (참고로 선형 계획법은 최적화 문제의 대표적인 유형이다).
홍길동 씨가 두 가지 종류의 빵을 판매하는데, 초코빵을 만들기 위해서는 밀가루 100g과 초콜릿 10g이 필요하고 밀빵을 만들기 위해서는 밀가루 50g이 필요하다. 재료비를 제하고 초코빵을 팔면 100원이 남고 밀빵를 팔면 40원이 남는다. 오늘 홍길동 씨는 밀가루 3000g과 초콜릿 100g을 재료로 갖고 있다. 만든 빵을 전부 팔 수 있고 더 이상 재료 공급을 받지 않는다고 가정한다면, 홍길동 씨는 이익을 극대화 하기 위해서 어떤 종류의 빵을 얼마나 만들어야 하는지 다음과 같이 선형 계획법을 이용하여 계산할 수 있다.

여기서 x1과 x2가 결정변수이다.
저 문제는 100x1 + 50x2 <= 3000, 10x1 <= 100, x1, x2 >=0을 만족하는 x1과 x2가운데, 100x1 + 40x2를 최대화하는 x1과 x2를 찾아라 라고 해석할 수 있다.
이 정도의 문제는 매우 간단하기 때문에 사실 유전 알고리즘을 사용할 필요가 없다.
여기서 간단하다는 것은 저 문제의 최적해(=정답)를 구하는 과정이 공식처럼 정의되어 있다는 것이다.
그런데 현실 문제는 저 정도로 간단하지 않은 것이 보통이다.
휴리스틱과 메타휴리스틱
이제 휴리스틱이라는 단어가 무엇인지 이해해보자.
위키피디아에서는 휴리스틱을 아래와 같이 정의하고 있다.
휴리스틱(heuristics) 또는 발견법(發見法)이란 불충분한 시간이나 정보로 인하여 합리적인 판단을 할 수 없거나, 체계적이면서 합리적인 판단이 굳이 필요하지 않은 상황에서 사람들이 빠르게 사용할 수 있게 보다 용이하게 구성된 간편추론의 방법이다.
어렵게 정의하고 있지만, 휴리스틱은 결국 그럴싸하게 대충 푸는 방법이라고 볼 수 있다.
외판원 문제 (traveling sales problem)을 예로 들어보자.
이 문제는 택배 기사가 현 위치에서 어느 순서대로 택배를 배달해야 최소한의 거리로 움직일 수 있는지를 찾는 문제로, 대표적인 NP 문제 (일단은 풀기 어려운 문제라고 이해하고 넘어가자)이다.
이 문제의 가장 직관적인 해법은 지금 있는 곳에서 가장 가까운 곳부터 배달을 가는 것이다 (즉 그리디하게 탐색하는 것)
시작점이 택배회사였다면, 택배회사에서 가장 가까운 A를 가고, 또 A에서는 A에서 가장 가까운 B를 가는 것이다.
그럴싸하지 않은가? 우리도 여러 군데를 들려야 하는 상황이라면, 가장 가까운 곳 먼저 들리는 경우가 많기 때문에, 그럴싸하고 합리적인 것처럼 보인다. 물론, 이 접근으로 찾은 답은 정답이 아닐 가능성이 훨씬 높다.
이처럼 문제를 알려진 공식으로 풀 수 없는 경우에 그럴싸하게 대충 푸는 접근을 휴리스틱이라고 할 수 있다.
그런데 휴리스틱은 문제마다 문제 상황에 맞는 경험이나 직관을 이용해야 하는 어려움이 있다.
그러니까 위에서 예를 들었던 그리디 서치는 외판원 문제에는 적용할 수 있을지 몰라도, 다른 문제에는 적용할 수 없다.
그래서 등장한 것이 메타 휴리스틱이고, 유전 알고리즘도 메타 휴리스틱에 속한다.
메타 휴리스틱은 휴리스틱이긴한데, 그 풀이 과정 등이 구조적으로 잘 정의되어 있어 대부분의 문제에 어려움없이 적용할 수 있는 휴리스틱을 말한다.
유전 알고리즘의 개념 이해하기
유전 알고리즘은 기본적으로 여러 개의 해로 구성된 해 집단을 만들고 평가한 뒤, 좋은 해를 선별해서 새로운 해 집단을 만드는 메타휴리스틱 알고리즘이다.
유전 알고리즘의 구성 등을 살펴보기 전에 작동 과정에 대해 개략적으로 이해하고 시작하자.
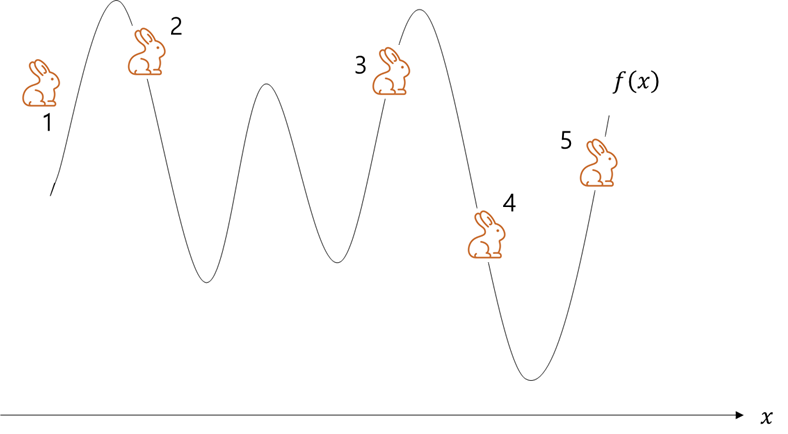
아래와 같이 함수 f(x)가 있고, x에 따른 f(x)의 최소값을 찾는 문제가 있다고 하자.
설명을 위해, 이 함수를 산이라고 하고, 해를 토끼, 그리고 산의 낮은 곳일수록 더 좋은 곳이라고 하자.
유전 알고리즘은 여러 토끼를 만들고, 좋은 환경에 우연히 있던 토끼들만 살아남아서 비슷한 위치에 자식을 만드는 과정을 통해, 가장 낮은 곳, 즉 최적값을 찾게 된다.

육안으로 어느 x가 가장 좋은지 알 수 있지만, 실제 문제에서는 저 그래프를 그리는 것 자체가 불가능한 경우가 대부분이다.
배우신 분들(?)은 미분을 하면 되지 않느냐라고 주장할 수도 있겠지만, 미분 자체가 불가능한 경우도 역시 매우 흔하다.
정답이 모두 정수여야 하는 정수 계획법 문제의 경우에는 어느 경우에서도 미분이 불가능할 것이다.
다시 설명으로 돌아와서 아래와 같이 5마리의 주황색 토끼를 만들어 임의로 배치한다.
우연히 4번과 5번 있던 토끼는 좋은 환경에 있었고, 1, 2, 3번은 그렇지 못하다.
즉, 4번과 5번이 적자이고, 나머지는 적자가 아니다.
이제 적자라서 살아남은 4번과 5번이 자식 a, b, c를 만든다.
자식들은 파란색으로 표시했다.
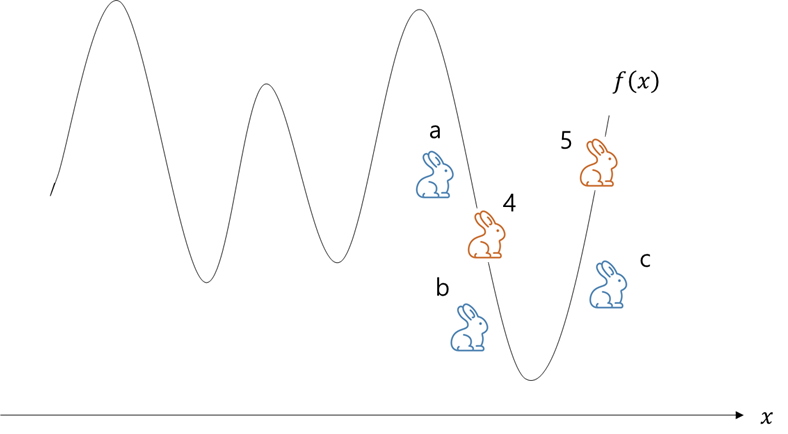
이제 다시 살펴보니, 부모보다 좋은 위치에 있는 자식 b와 c도 있고, 부모랑 비슷하거나 더 나쁜 위치에 있는 a도 생겼다.
그럼 이제 가장 적합한 b와 c가 살아남아 또 대를 이어 나갈 것이다.
그러다보면 언젠가는 최저점에 있는 토끼를 만나게 될테고, 다시말해 최적해를 구할 것이다.
주요 용어를 거의 사용하지 않고 설명한 내용이지만, 여기서 유전 알고리즘에 관한 몇 가지 인사이트를 얻을 수 있다.
(1) 해를 많이 만들면, 더 좋은 해를 찾을 가능성이 높다. 물론 시간은 더 소요될 것이다.
(2) 너무 잘난 해라면, 세대가 지나도 계속 세대를 구성하는 일원으로 남아있다.
(3) 다음 세대에서 자식을 만드는 부모의 수가 많을수록, 더 많은 해를 탐색할 수는 없다. 그렇지만 더 안정적일 것이다.
(4) 처음에 해들이 한 곳에 몰려있었다면 (특히, 1, 2번 위치), 세대를 거듭해도 좋은 해를 못 찾을 수도 있다.
유전 알고리즘 순서도
이제 본격적으로 유전 알고리즘에 대해 알아보자.
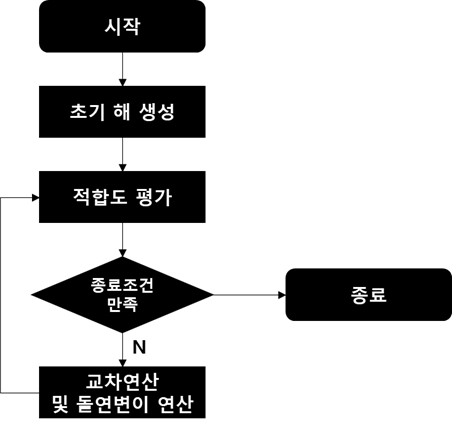
유전 알고리즘은 아래 그림과 같이 초기 해 생성, 적합도 평가, 교차 연산, 돌연변이 연산을 반복한다.
파라미터 정의
단계에는 포함하지 않았지만, 유전 알고리즘을 사용하려면 아래 내용을 미리 결정해야 한다.
- 해 표현 방법
- 최대 세대 수
- 종료 조건
- 세대 별 포함되는 해의 개수
- 교차 연산자
- 돌연변이 연산자
- 교차 비율
- 적합도 함수
- 돌연변이 비율 등
초기 해 생성
첫 번째 단계에서는 초기 해, 즉 첫 번째 세대의 해들을 생성한다.
이 과정에서는 보통 임의로 해를 생성하는데, 문제에 따라서 특정 조건에 맞는 해를 만들도록 설계하는 것이 유리하기도 하다. 그리고 여기서 가장 중요한 것은 해를 어떻게 표현할 것인가이다. 이를 줄여서 해 표현이라 하는데, 해 표현을 어떻게 하느냐에 따라서 문제 풀이가 쉬울 수도 있고 그렇지 않을 수도 있다. 유전 알고리즘을 많이 사용해본 사람과 그렇지 않은 사람의 차이가 사실 여기서 판가름난다.
가장 흔히 사용되는 해 구조는 다음과 같은 이진 벡터이다.

이진 벡터가 많이 사용되는 이유는 뒤에서 설명할 교차 연산이나 돌연변이 연산이 편리하기 때문이다.
외판원 문제처럼 순서를 결정하는 경우라면 이진 벡터보다는 각 위치가 도달한 장소의 인덱스를 나타내는 벡터로 표현하는 것이 적합할 수도 있다.
적합도 평가 및 해 선택
이 단계에서는 현재 세대에 있는 모든 해들을 적합도 함수라는 것을 이용하여 평가한다.
적합도는 보통 최적화 문제의 목적식을 그대로 사용하는 것이 일반적이다.
가령, 외판원 문제에서는 해의 적합도가 전체 이동 거리에 반비례할테고, 최대화 문제라면 해의 적합도가 목적식에 비례할 것이다.
적합도 평가 결과를 토대로 그 다음 세대를 만들 해들을 결정한다.
즉, 교차연산과 돌연변이 연산을 적합도가 우수한 해들에 적용하여 다음 세대에 속할 해를 만든다.
여기서 적합도가 높은 상위 N1개의 해를 선택하여 N2개의 해를 만드는 방식으로 다음 세대를 구성할 수도 있고 (세대별 해의 개수 (N) = N1 + N2), 혹은 적합도에 비례하게 해를 확률적으로 선택하여 해를 생성할 수도 있다.
전자의 경우에는 이전 세대의 해가 다음 세대로 그대로 넘어가고, 좋은 해들만 선별되므로 안정적이라는 장점이 있으나, 지역 최적에 빠질 위험이 있다.
후자의 경우에는 반대로 세대가 거듭될수록 이전에 고려하지 않았던 새로운 종류의 해를 탐색할 수 있으므로, 더 좋은 해를 찾을 수도 있지만, 수렴하지 못할 가능성이 크다.
교차 연산
교차 연산은 두 개의 부모 해를 바탕으로 자식 해를 만드는 연산을 말한다.
즉, 부모가 결합하여 자식을 낳는 과정을 모방한 것이 바로 교차 연산이다.
당연히 교차 연산을 해서 나온 해는 부모를 닮게 된다.
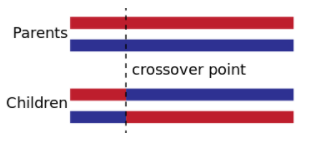
대표적인 교차 연산자로는 한 점 교차 연산자, 두 점 교차 연산자 등이 있다.
이들 교차 연산자는 교차 지점을 임의로 설정한 뒤, 교차 지점 앞쪽에서는 부모 1의 유전자를, 뒤쪽에서는 부모 2의 유전자를 가져와 새로운 자식을 만든다.
아래 그림에서 빨간색 해와 파란색 해가 교차되면서, 앞쪽이 빨갛고 뒤쪽이 파란 해와 앞쪽이 파랗고 뒤쪽이 빨간 해가 생성되었다.

돌연변이 연산
돌연변이 연산은 만들어진 자식 해를 일부 수정하는 것이다.
즉, 두 부모가 교차를 하더라도, 두 부모와는 완전히 일치하지 않는 그런 특성을 만들기 위한 연산이다.
세대를 거듭할수록 다양한 해를 찾지 않고 특정한 해로 빠르게 수렴하는 것을 막기 위한 연산이다.
아래와 같은 함수가 있고, 해가 주황색으로 표시된 상황을 보자.
여기서 저 네 개의 해를 바탕으로 교차 연산을 계속해서 진행하면 왼쪽 지역 최적에 빠져버리게 될 위험이 있다.
그런데 돌연변이 연산을 해주게 되면, 아예 엉뚱한 위치에 해를 만들기도 하므로, 우연히 좋은 해를 찾을 가능성이 높아지는 것이다.
다시 한 번 강조하지만, 돌연변이 연산을 한다고 해서 무조건 좋은 해를 찾을 수 있는 것은 아니다.
오히려 전역 최적에 가까워지다가 돌연변이 연산 때문에 전역 최적과 멀어지기도 한다.

대표적인 돌연변이 연산 방법으로는 flip-bit 변이 연산이 있다.
임의로 돌연변이를 할 자식을 선택하고, 자식의 유전 개체 (참고: 해를 유전자라하며, 해의 구성 요소 (즉 벡터의 구성 요소)를 유전 개체라 함)를 임의로 선택하여, 0이면 1로, 1이면 0으로 바꾸는 간단한 연산이다.
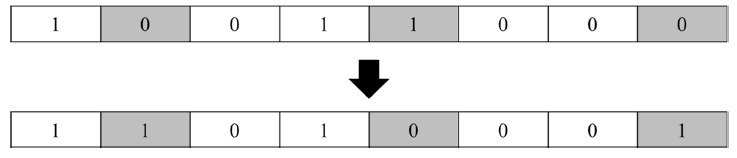
파이썬을 이용한 예제 풀이
최적화 문제를 소개하는 과정에서 나왔던 예제를 유전 알고리즘을 통해 풀어보자.
이 문제에서는 x1과 x2를 찾아야 한다.
해 구조는 다음과 같은 2 x 5 크기의 이진 행렬을 사용한다.

첫 번째 행은 x1과 관련이 있고, 두 번째 행은 x2와 관련이 있다.
즉, 위 구조의 해는 x1과 x2를 다음과 같이 표현한다.
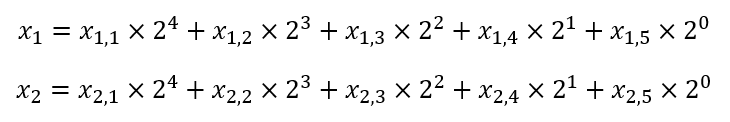
사실 이렇게 모두 양수만 표현하도록 설계한 이유는 세 번째 제약을 만족시키는 해를 만들기 위함이다 (이런게 유전 알고리즘을 사용할 때 매우 중요한 센스이다!).
해 표현을 제외한 유전 알고리즘의 주요 파라미터는 다음과 같이 설정한다.
- 최대 세대 수: 10
- 종료 조건: 최대 세대 수 도달
- 세대 별 포함되는 해의 개수: 20
- 교차 연산자: 1점 교차 연산
- 부모 수: 10
- 돌연변이 연산자: flip bit 돌연변이 연산
- 적합도 함수: 목적식 (제약을 만족못하면 0점)
- 돌연변이 비율: 10%
- 돌연변이 유전 개체 비율: 20%
이제 파이썬을 사용해서 유전 알고리즘의 각 단계를 함수 단위로 구현해보도록 하자.
유전 알고리즘을 사용할 수 있는 패키지가 있긴 하지만, 문제에 따라서 직접 정의해야 하는 부분이 많다보니 개인적으로는 numpy를 활용하는 것이 편리하다.
먼저, numpy를 임포트해주자.
import numpy as np
그리고 N개의 초기 해를 생성하는 함수를 정의하자.
이 함수는 random.randint를 사용하여 0과 2사이 중 하나를 선택하여 (N, 2, 5) shape의 배열을 생성한다.
즉, 0과 1로만 구성되는 (N, 2, 5) shape의 배열을 만드는 것이며, N은 결국 해의 개수, (2, 5)는 해의 구조 (행렬 구조)라고 볼 수 있다.
def generate_initial_population(N):
initial_population = np.random.randint(0, 2, (N, 2, 5))
return initial_population
이제 각각의 해를 평가하는 적합도 함수를 만들자.
제약이 문제에 포함되어 있으므로 제약을 어기는 경우에는 적합도를 0으로 주도록 하자.
먼저 2 * 5 크기의 행렬이 입력되면, 여기서 x1과 x2를 계산한다.
그리고 문제의 제약을 만족하는지 여부를 확인해서, 모두 만족하면 목적식으로 적합도를 평가하고, 하나라도 만족하지 못하면 적합도를 0으로 설정한다.
def evaluate_fitness(solution):
x1 = sum([2**(4-i) * solution[0][i] for i in range(5)])
x2 = sum([2**(4-i) * solution[1][i] for i in range(5)])
constraint_1 = (100 * x1 + 50 * x2) <= 3000
constraint_2 = (10 * x1) <= 100
if constraint_1 and constraint_2:
fitness_value = 100 * x1 + 40 * x2
else:
fitness_value = 0 # 제약을 하나라도 위반하면 적합도 0점
return fitness_value
이제 한 세대에서 두 개의 해를 선택하여 1점 교차 연산을 수행하는 함수를 정의하자.
이 함수는 두 개의 해 (solution1, solution2)를 입력받아 교차 지점을 1과 5사이에서 임의로 선택하여 자식을 만든다.
해 자체가 행렬이기 때문에 교차 지점을 각 행마다 설정했다.
자세히 살펴보면, 각 행마다 교차 지점은 1, 2, 3 중 하나를 선택하는데, 0이나 4가 교차지점이 되면 사실상 하나의 부모의 유전자가 그대로 내려오는 것이기 때문에 0과 4는 제외하였다.
그리고 자식 해를 빈 배열로 생성한 뒤, 0번째 행과 1번째 행을 각각 부모들의 유전자로 채운다.
리스트로 만들어서 더하는 방식도 괜찮지만, 그렇게 되면 ndarray와 리스트를 왔다갔다하면서 문제가 생길 위험이 있기 때문에, empty 함수를 사용했다.
def crossover(solution1, solution2):
crossover_point_1 = np.random.randint(1, 4) # x1에 대한 교차 지점
crossover_point_2 = np.random.randint(1, 4) # x2에 대한 교차 지점
child = np.empty((2, 5)) # 자식을 빈 배열로 생성
# 부모 유전자 가져오기
child[0][:crossover_point_1] = solution1[0][:crossover_point_1]
child[0][crossover_point_1:] = solution2[0][crossover_point_1:]
child[1][:crossover_point_2] = solution1[1][:crossover_point_2]
child[1][crossover_point_2:] = solution2[1][crossover_point_2:]
return child이제 돌연변이 연산을 정의하자.
p는 각 개체에서 돌연변이가 일어날 확률이다.
해의 모든 인덱스를 row와 col로 순회하면서, 각 위치마다 난수를 생성한 뒤, 그 난수가 p보다 작다면 (즉, p의 확률로), 그 위치에 있는 값을 바꿔준다.
여기서 유용한 두 가지 테크닉을 짚고 넘어가자.
- x = 1 - x는 x가 0이면 1로, 1이면 0으로 바꾸는데 사용
- if 난수 < p는 결국 p의 확률로 선택하는데 사용
def mutation(child, p):
for row in range(2):
for col in range(5):
if np.random.random() < p:
child[row, col] = 1 - child[row, col]
return child이제 함수 정의는 끝났으니, 함수들을 이용하여 유전 알고리즘을 구현하자.
먼저, 파라미터를 이렇게 정의하자.
num_iter = 10 # 세대 수
N = 20 # 한 세대에 포함되는 해의 개수
N_P = 10 # 부모 개수
mutation_sol_prob = 0.1 # 유전자(해)가 돌연변이일 확률
mutation_gene_prob = 0.2 # 유전 개체가 돌연변이일 확률
그리고나서 메인 코드를 작성한다.
가장 먼저 초기 해를 생성하고, 지금까지 찾은 최대 적합도를 초기화한다.
그리고 각 이터레이션마다 현재 세대를 평가하고, 현재 세대에 지금까지 찾은 최대 적합도보다 큰 적합도를 갖는 해가 있다면, 그 해를 best_solution에, 그 해의 적합도를 best_score에 저장한다.
그리고 fitness_value_list를 기준으로 상위 N_P개의 해를 선택하여 parents에 저장한다.
그리고 한 세대에 포함되야 하는 해의 개수에서 부모의 개수를 뺀 만큼 자식을 생성한 뒤, 20%의 확률로 돌연변이 연산을 적용한 자식을 new_population에 추가한다.
# 초기 해 생성
current_population = generate_initial_population(N)
best_score = -1 # 지금까지 찾은 최대 적합도 초기화
for _ in range(num_iter - 1):
# 해 평가 수행
fitness_value_list = np.array([evaluate_fitness(solution) for solution in current_population])
# 지금까지 찾은 최대 적합도보다 현세대에 있는 최대 적합도가 크다면 업데이트
if fitness_value_list.max() > best_score:
best_score = fitness_value_list.max()
best_solution = current_population[fitness_value_list.argmax()]
# 적합도 기준 상위 N_P개 해 선정 (값이 큰 순으로 정렬하기 위해 -를 붙임)
parents = current_population[np.argsort(-fitness_value_list)]
# 새로운 해 집단 정의
new_population = parents
# 두 개의 부모를 선택하면서 자식 생성
for _ in range(N - N_P): # N - N_P = 생성해야 하는 자식 개수
# 부모 선택
parent_1_idx, parent_2_idx = np.random.choice(N_P, 2, replace = False)
parent_1 = parents[parent_1_idx]
parent_2 = parents[parent_2_idx]
# 자식 생성
child = crossover(parent_1, parent_2)
# mutation_sol_prob의 확률로 돌연변이 연산 수행
if np.random.random() < mutation_sol_prob:
child = mutation(child, mutation_gene_prob)
# new_population에 child 추가 (child 구조가 (2, 5)라서 vstack이 안되므로, 구조를 변경)
new_population = np.vstack([new_population, child.reshape(1, 2, 5)])이렇게 찾은 해는 다음과 같다.
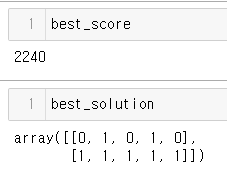
best_solution을 뜯어보면, x1 = 10, x2 = 31인데, 주어진 해 구조에서는 최적임을 쉽게 알 수 있다.
다 풀고 나서 실수를 알아차렸는데, 2*5크기가 아니라 2*6크기의 해 구조를 정의했으면 최적해를 찾았을 것이다...
데이터 분석 서비스가 필요한 분은 아래 링크로!
데이터사이언스 박사의 데이터 분석 서비스 드립니다. | 150000원부터 시작 가능한 총 평점 5점의 I
78개 총 작업 개수 완료한 총 평점 5점인 데이터사이언스박사의 IT·프로그래밍, 데이터 분석·시각화 서비스를 68개의 리뷰와 함께 확인해 보세요. IT·프로그래밍, 데이터 분석·시각화 제공 등 150
kmong.com
'데이터사이언스 > 최적화' 카테고리의 다른 글
| Particle Swarm Optimization, 입자 군집 최적화 (0) | 2022.12.25 |
|---|---|
| 베이지안 최적화 (1) 블랙박스 최적화 문제 (0) | 2022.05.20 |
| 유전 알고리즘을 이용한 특징 선택 (0) | 2022.04.06 |
| [논문 리뷰] 베이지안 최적화 (Bayesian Optimization) (0) | 2022.01.19 |



