
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 주요 파라미터
- 공공데이터
- 퀀트 투자 책
- 데이터 분석
- 주가데이터
- 판다스
- 경력기술서 첨삭
- 자기소개서
- 과제전형
- 데이터사이언티스트
- 대학원
- 파이썬
- AutoML
- 이력서 첨삭
- 주식데이터
- 하이퍼 파라미터 튜닝
- 경력 기술서
- 데이터 사이언티스트
- 커리어전환
- 퀀트
- 데이터 사이언스
- 데이터사이언스
- 머신러닝
- 사이킷런
- 코딩테스트
- sklearn
- 하이퍼 파라미터
- pandas
- 랜덤포레스트
- 데이터분석
- Today
- Total
GIL's LAB
Open DART를 이용한 기업공시 수집 (2) 주당 배당금 수집 본문
개요
이번 포스팅에서는 OpenDartReader를 이용하여 코스피/코스닥 기업의 주당 배당금을 수집해보겠습니다.
주당 배당금이 높으면 그 자체로 투자할 가치가 있으며 (물론 배당금에 비해 주가 하락이 심한 경우에는 전혀 그렇지 않습니다), 배당금이 높은 기업일수록 주가 상승률이 높다라는 관계가 있다고 합니다 (역시 자세한 내용은 실험을 통해 검증하겠습니다).
관련 패키지 설치와 사용 방법은 이전 포스팅을 참고해주시기 바랍니다.
report 메서드
OpenDartReader의 객체의 report 메서드는 사업보고서의 주요정보를 가져오며, 주요 인자는 다음과 같습니다.
dart.report(corp, key_word, bsns_year, reprt_code)여기서 dart는 임의의 OpenDartReader 객체를 나타내며, 각 인자에 대한 설명은 다음과 같습니다.
| 인자 | 유형 | 기본값 | 내용 |
| corp | 문자열 | 없음 | 검색대상 회사의 종목코드 (고유번호, 회사이름도 가능함) |
| key_word | 문자열 | 없음 | ‘증자’: 증자(감자) 현황, ‘배당’: 배당에 관한 사항, ‘자기주식’: 자기주식 취득 및 처분 현황, ‘최대주주': 최대주주 현황, '최대주주변동': 최대주주 변동 현황, '소액주주': 소액주주현황, '임원': 임원현황, '직원': 직원현황, '임원개인보수': 이사ㆍ감사의 개인별 보수 현황, '임원전체보수': 이사ㆍ감사 전체의 보수현황, '개인별보수': 개인별 보수지급 금액(5억이상 상위5인), '타법인출자': 타법인 출자현황 |
| bsns_year | 문자열 혹은 정수형 | 없음 | 사업연도 |
| reprt_code | 보고서 코드 | ‘11011’ | '11013':1분기보고서, '11012':반기보고서, '11014':3분기보고서, '11011':사업보고서 |
이 메서드의 반환값은 데이터프레임이며, 이 데이터프레임을 구성하는 컬럼은 key_word에 따라 달라집니다.
심지어는 같은 key_word를 입력하더라도 컬럼 구성이 약간씩 다르기도 합니다. 예를 들어, key_word에 “배당”을 입력하는 경우에 주요 컬럼은 다음과 같습니다.
- se: 구분. 유상증자(주주배정), 전환권행사 등
- stock_knd: 주식 종류
- thstrm: 당기
- frmtrm: 전기
- lwfr: 전전기
설명을 위해, 아래 코드를 사용하여 SK하이닉스의 2020년 사업보고서에서 배당 정보를 확인해보겠습니다.
display(dart.report("SK하이닉스", "배당", 2020, "11011"))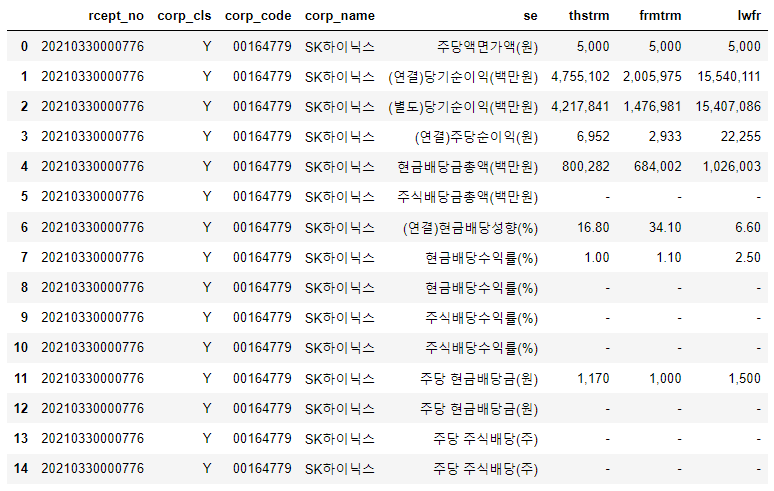
위 출력 결과에서 우리가 관심이 있는 행은 11번째 행에 있는 주당 현금배당금(원)으로 당기값이 1,170원입니다.
여기서 미리 알 수 있는 점은 se 컬럼이 주당 현금배당금(원)인지를 기준으로 필터링하고, 하이픈이 있는 행은 제거해야 한다는 것입니다.
비슷한 방법으로 삼성전자도 확인해보겠습니다. SK하이닉스와는 다르게 우선주가 있어, stock_knd라는 컬럼이 추가로 있음을 알 수 있습니다.
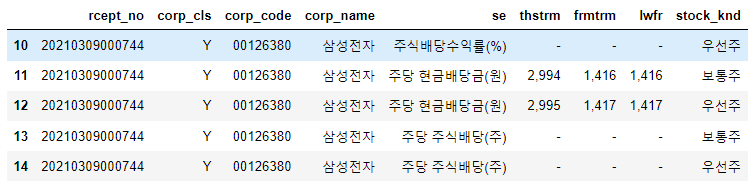
마지막으로, 배당이 없는 기업의 경우에는 주당 현금배당금(원) 옆에 있는 값이 모두 하이픈(-)으로 되어 있습니다.
수집 과정
이제 report 메서드를 이용하여 모든 코스피/코스닥 종목의 2015년 - 2020년의 주당 배당금을 구해보겠습니다.
먼저, OpenDartReader 객체를 다음과 같이 생성합니다.
역시 my_api에는 자신의 인증키를 넣어야 합니다 (인증키 받는 방법은 지난 포스팅을 참고해주세요!)
import OpenDartReader
my_api = "ce22390b1b4df0cdd2e09c5dc44e71c20f52a333"
dart = OpenDartReader(my_api)
그 다음으로 수집할 종목 목록을 아래와 같이 정리하겠습니다.
FinanceDataReader를 사용하여 코스피, 코스닥 종목을 모두 불러오고, Market과 Region을 기준으로 필터링하여 종목명만 가져와서 이를 stock_name_list에 저장합니다.
여기서 Market을 기준으로 필터링하는 것은 Market이 KOSPI 혹은 KOSDAQ인 행만 필터링하는 것이며, Region을 기준으로 필터링하는 것은 결측이 아닌 행만 필터링하는 것입니다.
선물의 경우에는 배당 정보와 지역 정보가 당연히 없기에 제거하는 것입니다.
import FinanceDataReader as fdr # FinanceDataReader 모듈 불러오기
stock_list = fdr.StockListing('KRX') # 코스피, 코스닥, 코넥스 종목 모두 불러오기
stock_list = stock_list.loc[stock_list['Market'].isin(["KOSPI", "KOSDAQ"])] # Market 기준 필터링
stock_name_list = stock_list.loc[stock_list['Region'].notnull(), 'Name'].tolist() # 선물과 같이 KOSPI에는 있으나 배당이 없을수밖에 없는 종목은 제외여기서 잠깐! 에러가 발생하는 경우
위 코드에서 KeyError: 'Region'이 발생한다면 최신 버전의 FinanceDataReader를 사용하기 때문입니다. 최신 버전에서는 StockListing 함수는 아래 컬럼을 갖는 데이터프레임을 반환합니다.
Index(['Code', 'ISU_CD', 'Name', 'Market', 'Dept', 'Close', 'ChangeCode',
'Changes', 'ChagesRatio', 'Open', 'High', 'Low', 'Volume', 'Amount',
'Marcap', 'Stocks', 'MarketId'],
dtype='object')Region 컬럼이 없기 때문에 오류가 발생하는 것입니다.
다행히도 선물 종목은 여기에 없으므로 stock_name_list를 정의하는 라인을 다음과 같이 수정하면 됩니다.
stock_name_list = stock_list['Name'].tolist()만약 우량주 정보도 제거하고 싶다면 아래 코드(맨 뒤에 우로 끝나는 종목을 제거)를 활용하기 바랍니다.
stock_name_list = stock_list.loc[~stock_list['Name'].str.endswith('우'), 'Name'].tolist()

위 오류를 말씀해주신 구독자분께 감사드립니다 (비밀댓글로 다셔서 닉네임은 공개하지 않겠습니다)
이제 종목명과 연도를 입력받아, 주당 배당금을 반환하는 함수를 작성하겠습니다.
코드가 조금 길지만 사실 그렇게 어려운 코드는 아닙니다.
먼저, 입력받은 stock_name과 year를 바탕으로 해당 종목의 해당 연도의 사업보고서에서 배당 부분을 가져와 stock_name_report에 저장합니다.
그리고 stock_name_report가 None이라면, 보고서가 없는 것이므로 배당 정보도 없습니다. 따라서 np.nan을 리턴합니다.
stock_name_report가 있다면, se 컬럼이 주당 현금배당금(원)인 행을 필터링하고, 첫 번째 행의 값을 가져옵니다.
첫 번째 행에서 각 기 (당기, 전기, 전전기)가 하이픈으로 되어 있다면 0으로 바꾸고, 콤마를 제거하는 방식으로 숫자로 변환하여 전전기, 전기, 당기 값을 반환합니다.
stock_name_report에 se 컬럼이 없는 경우 오류가 발생해서 try ~ except 구문으로 오류를 무시하는 부분을 추가했습니다.
import numpy as np
def find_divdends(stock_name, year):
try:
stock_name_report = dart.report(stock_name, "배당", year, "11011") # 데이터 가져오기
except:
stock_name_report = None
if stock_name_report is None: # 리포트가 없다면 (참고: 리포트가 없으면 None을 반환함)
return np.nan, np.nan, np.nan
else:
# 필터링: se컬럼이 주당 현금배당금(원)인 첫 번째 행만 가져옴
try:
stock_name_report = stock_name_report.loc[(stock_name_report['se'] == '주당 현금배당금(원)')].iloc[0]
# 하이픈이 포함되어 있으면 0으로 바꾸고, 콤마를 제거하여 숫자로 변환함
# 하이픈과 콤마가 동시에 포함되어 있진 않기에 가능
thstrm_divdends = int(stock_name_report['thstrm'].replace('-', '0').replace(',', ''))
frmtrm_divdends = int(stock_name_report['frmtrm'].replace('-', '0').replace(',', ''))
lwfr_divdends = int(stock_name_report['lwfr'].replace('-', '0').replace(',', ''))
return lwfr_divdends, frmtrm_divdends, thstrm_divdends
except:
return np.nan, np.nan, np.nan이제 이 함수를 전체 종목과 연도에 적용해보겠습니다.
앞서 정의했던 stock_name_list를 순회하면서, stock_name에 대해 2013년부터 2020년까지의 배당금을 찾은 뒤 record에 추가하는 방식으로 데이터를 정리합니다. 전전기와 전기 값을 가져오면 되므로 2015년, 2018년, 2020년 보고서만 찾은 것입니다. 당기를 다 가져오게 되면, 일일 조회수를 초과하기 때문에 문제가 생깁니다 (물론 이틀에 거쳐 해도 됩니다..)
여기서 time.sleep을 통해, 하나의 레코드가 수집되면 0.5초씩 프로그램을 재웁니다.
import time
data = []
for idx, stock_name in enumerate(stock_name_list):
print(idx+1, "/", len(stock_name_list)) # 현재까지 진행된 상황 출력
record = [stock_name] # 레코드 초기화
for year in [2015, 2018, 2020]:
lwfr_divdends, frmtrm_divdends, thstrm_divdends = find_divdends(stock_name, year) # 배당금 가져오기
if year != 2020:
record += [lwfr_divdends, frmtrm_divdends, thstrm_divdends]
else:
record += [frmtrm_divdends, thstrm_divdends] # 2018년이 중복되므로
data.append(record)
time.sleep(0.5) # 0.5초씩 재움
이렇게 수집한 데이터를 데이터프레임으로 변환하고, 배당목록이라는 파일로 저장해줍니다.
import pandas as pd
data = pd.DataFrame(data,
columns = ["stock_name", "2015", "2016", "2017", "2018", "2019", "2020"])
data.to_csv("../../데이터/배당목록.csv", index = False)
데이터 분석 서비스가 필요한 분은 아래 링크로!
데이터사이언스 박사의 데이터 분석 서비스 드립니다. | 150000원부터 시작 가능한 총 평점 5점의 I
78개 총 작업 개수 완료한 총 평점 5점인 데이터사이언스박사의 IT·프로그래밍, 데이터 분석·시각화 서비스를 68개의 리뷰와 함께 확인해 보세요. IT·프로그래밍, 데이터 분석·시각화 제공 등 150
kmong.com
'퀀트 투자 > 데이터 수집' 카테고리의 다른 글
| Open DART를 이용한 기업공시 수집 (4) 전체 재무제표 수집 (5) | 2021.12.15 |
|---|---|
| Open DART를 이용한 기업공시 수집 (3) 주요 재무지표 수집 및 가공 (12) | 2021.10.12 |
| Open DART를 이용한 기업공시 수집 (1) 환경 설정 (0) | 2021.10.11 |
| 오픈 API를 이용한 주식 데이터 수집하기 (3) 분틱 코스피/코스닥 데이터 수집 방법 (1) | 2021.09.17 |
| 파이썬을 이용하여 현금흐름표에서 주요 지표 뽑아내기 (16) | 2021.09.08 |


