
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 경력기술서 첨삭
- 주가데이터
- 이력서 첨삭
- 코딩테스트
- 하이퍼 파라미터
- 판다스
- 커리어전환
- 데이터 사이언티스트
- 주식데이터
- 머신러닝
- 퀀트 투자 책
- pandas
- sklearn
- 데이터 분석
- 자기소개서
- 퀀트
- 데이터분석
- 과제전형
- 데이터 사이언스
- AutoML
- 공공데이터
- 하이퍼 파라미터 튜닝
- 대학원
- 사이킷런
- 데이터사이언스
- 주요 파라미터
- 랜덤포레스트
- 데이터사이언티스트
- 경력 기술서
- 파이썬
- Today
- Total
GIL's LAB
파이썬을 이용하여 현금흐름표에서 주요 지표 뽑아내기 본문
본 포스팅에서는 종목별로 현금흐름표에서 주요 지표를 뽑아내서 저장하도록 한다.
투자 시 현금흐름표에서 반드시 확인해야 할 사항은 세 가지이다.
- 영업활동 현금흐름: 기업의 영업활동으로 인한 현금흐름으로 양수여야 함
- 투자활동 현금흐름: 장비, 기계, 부동산 등을 구입하는 유무형 자산의 취득과 처분에 관련된 현금흐름으로, 정상적인 기업은 이 항목이 음수이지만, 회계상의 이유로 양수가 나오는 경우도 있음
- 재무활동 현금흐름: 금융 기관으로부터 돈을 빌리거나 갚은 것을 말하며, 음수는 돈을 갚은 것을 의미하고 양수는 돈을 빌린 것을 의미함
본 포스팅에서는 현금흐름표에서 저 세가지 항목을 파이썬을 이용하여 추출하도록 한다.
재무정보 다운로드
가장 먼저, Open Dart에 접속하여, 재무정보를 일괄다운로드하자.
링크는 https://opendart.fss.or.kr/disclosureinfo/fnltt/dwld/main.do 이다.
해당 링크에 접속하면 아래와 같이 연도별 모든 기업의 재무상태표, 손익계산서, 현금흐름표, 자본변동표를 다운로드할 수 있다.

2021년도부터 2016년도까지 탭을 클릭하면서 모든 현금흐름표를 다운로드하고, 다운로드한 압축파일을 하나의 폴더에 몰아놓는다. 필자는 아래와 같이 기러기라는 폴더에 다 몰아놓았다.

그리고나서 모든 파일의 압축을 푼다. 이때, 압축이 풀린 파일은 이 폴더에 있어야 하고, 편의를 위해 압축을 푼 zip 파일은 삭제한다.
압축을 풀고 난 모습은 다음과 같다.

각 흐름표에서 필요한 내용을 추출하기 전에, 몇 가지를 확인하자.
일단, 파일명 뒤쪽에 _연결_이 있는 파일이 있고 그렇지 않은 파일이 있다. _연결_이 있는 파일은 연결재무제표이고 그렇지 않은 파일은 별도재무제표이다. 필자는 아래 기사를 믿고 연결재무제표를 쓰도록 한다.
https://news.mt.co.kr/mtview.php?no=2018091308003358480

파일 구성 확인
그러면 이제 파일 하나를 켜서 어떻게 구성되어 있는지를 확인해보자.
2016_1분기보고서_04_현금흐름표_연결_20210317.txt를 켜서 스크롤을 약간 오른쪽으로 옮기면 아래와 같은 내용을 볼 수 있다.

각 항목이 탭으로 구분되어 있고, 하나의 줄이 한 기업의 특정 항목 값 (예를 들어 첫 줄은 3S라는 기업의 영업활동현금흐름)임을 알 수 있다. 더 자세히 설명하기 위해 2016년 1분기의 3S 기업의 연결현금흐름표를 보자.
이 연결현금흐름표의 각 줄이 위의 텍스트 파일로 저장된 것을 볼 수 있다.
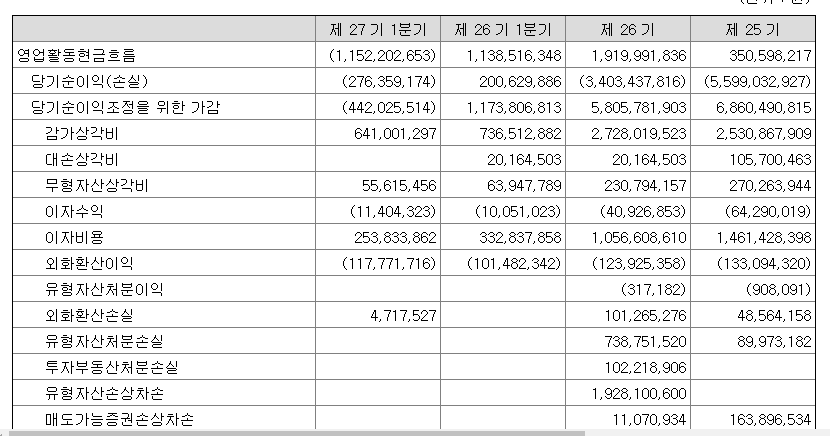
그러면 이제 우리가 해야할 것은 연결현금흐름표를 실행하여 기업별 영업활동, 투자활동, 재무활동 현금흐름을 가져오는 것이다.
파이썬을 활용한 데이터 병합
이제 파이썬을 실행해서 작업을 시작하자.
먼저, os 모듈과 pandas 모듈을 불러오고 압축이 풀린 파일들이 있는 경로와 파싱한 결과를 저장할 경로를 설정하자.
import os
import pandas as pd
input_path = "C:/Users/Gilseung/Downloads/기러기"
output_path = "C:/Users/Gilseung/Desktop/Jupyter/GILLAB/QUANT_DATA/201609~202108/재무제표"이제 각 년도와 분기를 돌면서 파일을 열 것이다.
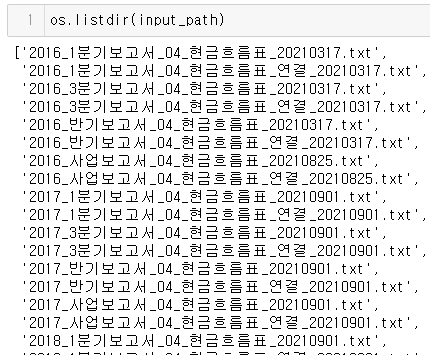
먼저, os.listdir 함수를 통해 input_path 내에 있는 파일들의 이름을 확인하자.
우리는 여기서 _연결_이라는 단어가 들어간 파일만 가져올 것이다.
각 파일을 열고 필요한 정보만 추출하는 함수를 만들어보자.
예시를 위해, 2016_1분기보고서_04_현금흐름표_연결_20210317.txt를 가지고 함수를 작성해보자.
먼저 이 파일을 다음과 같이 열자.
f = open(input_path + "/2016_1분기보고서_04_현금흐름표_연결_20210317.txt")그리고 각 라인을 순회하면서, "영업활동현금흐름", "투자활동현금흐름", "재무활동현금흐름"이라는 단어가 있는 라인만 필터링해야 한다. 필터링된 라인에서는 탭으로 구분한 뒤, 기업명과 각 단어 바로 뒤에 있는 값(최신값이 바로 뒤에 있음)을 가져올 것이다.
설명을 위해서 "영업활동현금흐름"이 처음 나올 때까지만 작업하는 코드를 만들어보자.
line = f.readline() # 한 줄 읽기
while line: # 읽을게 있을 때까지 반복
if "영업활동현금흐름" in line: # 영업활동현금흐름이 있으면,
s_line = line.split("\t") # 탭을 기준으로 분할
code = s_line[1][1:-1] # 코드는 1번째 위치에 있고 [00660]처럼 되어 있음
name = s_line[2] # 회사명은 2번째 위치에 있음
idx = s_line.index("영업활동현금흐름") # 영업활동현금흐름이 있는 위치를 찾고
value = s_line[idx+1] # 바로 뒤에 있는 값을 사용
value = int(value.replace(',', '')) # 콤마가 있는 경우가 있어서 콤마를 삭제하고 int로 변경
print(code, name, value)
break
line = f.readline() # 다음 줄 읽기출력은 (060310, 3S, -1152202653)이 나옴을 확인할 수 있다.
자. 그러면 위 내용을 참고하여 파일이 입력되었을 때, key가 (종목코드,종목명)이고 value가 각각 영업활동현금흐름, 투자활동현금흐름, 재무활동현금흐름인 사전을 만들어보자.
우리의 최종목표는 영업활동현금흐름, 투자활동현금흐름, 재무활동현금흐름을 나타내는 세 개의 데이터프레임을 만드는 것이고, 각 데이터 프레임의 컬럼은 분기, 인덱스는 종목코드 혹은 종목명이 되도록 할 것이다.
동일한 라인 작성을 방지하기 위해, word를 순회하도록 정의하였다.
def parsing_cash_flow(file_name):
f = open(input_path + "/" + file_name)
line = f.readline() # 한 줄 읽기
investment = dict() # 투자활동현금흐름
finance = dict() # 재무활동현금흐름
sales = dict() # 영업활동현금흐름
while line: # 읽을게 있을 때까지 반복
for word in ["투자활동현금흐름", "재무활동현금흐름", "영업활동현금흐름"]:
if word in line: # 영업활동현금흐름이 있으면,
s_line = line.split("\t") # 탭을 기준으로 분할
code = s_line[1][1:-1] # 코드는 1번째 위치에 있고 [00660]처럼 되어 있음
name = s_line[2] # 회사명은 2번째 위치에 있음
try:
idx = s_line.index(word) # 영업활동현금흐름이 있는 위치를 찾고
except:
for i, temp in enumerate(s_line):
if word in temp: # I. 영업활동현금흐름처럼 되어 있는 경우도 있어서 예외 처리
idx = i
break
try:
value = s_line[idx+1] # 바로 뒤에 있는 값을 사용
value = int(value.replace(',', '')) # 콤마가 있는 경우가 있어서 콤마를 삭제하고 int로 변경
except:
value = 0 # 값이 비어있는 경우에는 0으로 넣기
if word == "투자활동현금흐름":
investment[(code, name)] = value # (code, name)을 키로하여 value를 추가
elif word == "재무활동현금흐름":
finance[(code, name)] = value # (code, name)을 키로하여 value를 추가
else:
sales[(code, name)] = value # (code, name)을 키로하여 value를 추가
line = f.readline() # 다음 줄 읽기
return investment, finance, sales이제 이 함수의 결과물을 살펴보자.
file_name = "2016_1분기보고서_04_현금흐름표_연결_20210317.txt"
investment, finance, sales = parsing_cash_flow(file_name)
보다시피 사전이며, 이대로 데이터를 정리하기는 어렵다.
따라서 이 사전을 시리즈로 변환한 다음에, reset_index를 이용하여 인덱스를 컬럼으로 빼내는 방식으로 데이터프레임으로 만든 뒤, 컬럼명을 변환하는 작업을 하도록 하자.
그러면 아래와 같이 컬럼 세개로 구성된 데이터프레임이 되게 된다. 각각의 컬럼명을 종목코드,종목명,2016-1Q로 바꾸도록 한다.
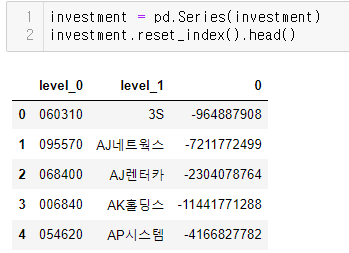
이제 이 전체 내용을 반복하도록 하자.
단, 각 파일에서 만들어지는 investment, finance, sales는 종목코드, 종목명을 기준으로 merge를 해나가도록 하자.

이제 전체 파일에 대해 순회하도록 하자.
먼저 코스피종목과 코스닥종목에서 현금흐름표가 있어야 하는 실제 기업 목록을 가져온다.
이는 merge를 할 때 특정 분기에 값이 없어서 전체 데이터가 손실되는 것을 방지하기 위함이다.
# 값이 없는 것을 NaN으로 채우기 위해 가져옴
stock_list = pd.concat([fdr.StockListing("KOSPI"), fdr.StockListing("KOSDAQ")]).dropna()
stock_list = stock_list[['Symbol', 'Name']]
stock_list.columns = ["종목코드", "종목명"]
그리고 특정 분기에 대해 베이스가 되는 데이터프레임을 만든다.
pd.merge를 통해, stock_list에는 있는데 investment_df 등에 없는 종목의 2016-1Q값은 NaN으로 채운다.
# 2016년 1분기로 먼저 수행 (merge를 쉽게하기 위함)
investment, finance, sales = parsing_cash_flow("2016_1분기보고서_04_현금흐름표_연결_20210317.txt")
investment_df = pd.Series(investment).reset_index()
investment_df.columns = ["종목코드", "종목명","2016-1Q"]
investment_df = pd.merge(stock_list, investment_df, on = ["종목코드", "종목명"], how = "left")
finance_df = pd.Series(finance).reset_index()
finance_df.columns = ["종목코드", "종목명","2016-1Q"]
finance_df = pd.merge(stock_list, finance_df, on = ["종목코드", "종목명"], how = "left")
sales_df = pd.Series(sales).reset_index()
sales_df.columns = ["종목코드", "종목명","2016-1Q"]
sales_df = pd.merge(stock_list, sales_df, on = ["종목코드", "종목명"], how = "left")그 후에 나머지 파일들을 불러와서 베이스 데이터프레임이랑 병합을 한다.
for year in [2016, 2017, 2018, 2019, 2020, 2021]:
for quarter_name, quarter in zip(["1분기", "반기", "3분기", "사업"], ["1Q", "2Q", "3Q", "4Q"]):
if year == 2016 and quarter == "1Q": # 2016 1분기는 이미 했으므로 패스
continue
for file in os.listdir(input_path):
if ("연결" in file) and (str(year) + "_" in file) and (quarter_name in file):
# 조건에 만족하는 파일을 찾으면 해당 파일을 열어서 정리
investment, finance, sales = parsing_cash_flow(file)
investment = pd.Series(investment).reset_index()
investment.columns = ["종목코드", "종목명","{}-{}".format(year, quarter)]
investment_df = pd.merge(investment_df, investment, on = ["종목코드", "종목명"]) # 데이터 병합
finance = pd.Series(finance).reset_index()
finance.columns = ["종목코드", "종목명","{}-{}".format(year, quarter)]
finance_df = pd.merge(finance_df, finance, on = ["종목코드", "종목명"])
sales = pd.Series(sales).reset_index()
sales.columns = ["종목코드", "종목명","{}-{}".format(year, quarter)]
sales_df = pd.merge(sales_df, sales, on = ["종목코드", "종목명"])마지막으로 해당 파일들을 저장하면 끝!
investment_df.to_csv(output_path + "/" + "투자활동현금흐름.csv", index = False, encoding = "cp949")
finance_df.to_csv(output_path + "/" + "재무활동현금흐름.csv", index = False, encoding = "cp949")
sales_df.to_csv(output_path + "/" + "영업활동현금흐름.csv", index = False, encoding = "cp949")전체 코드는 아래에서 받을 수 있다.
수집하고 싶은 금융 데이터나 실험하고 싶은 퀀트 관련 아이디어가 있으면 댓글로 남겨주세요!
관련 포스팅을 준비하도록 하겠습니다!

'퀀트 투자 > 데이터 수집' 카테고리의 다른 글
| Open DART를 이용한 기업공시 수집 (1) 환경 설정 (0) | 2021.10.11 |
|---|---|
| 오픈 API를 이용한 주식 데이터 수집하기 (3) 분틱 코스피/코스닥 데이터 수집 방법 (1) | 2021.09.17 |
| 아이투자에서 투자지표 (EPS, PER, 영업이익률 등) 크롤링하기 (0) | 2021.09.08 |
| 전종목 기업 리포트 크롤링 (4) | 2021.09.06 |
| FinanceDataReader를 이용한 주식, 비트코인 및 경제 지표 데이터 수집 (7) | 2021.09.05 |


