
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 코딩테스트
- 머신러닝
- 데이터 사이언티스트
- 주요 파라미터
- 경력기술서 첨삭
- 이력서 첨삭
- 데이터사이언티스트
- 과제전형
- 주식데이터
- 하이퍼 파라미터 튜닝
- 주가데이터
- 판다스
- 파이썬
- 사이킷런
- 경력 기술서
- 커리어전환
- 랜덤포레스트
- 대학원
- 데이터사이언스
- AutoML
- 공공데이터
- 데이터분석
- 데이터 사이언스
- 퀀트 투자 책
- pandas
- sklearn
- 데이터 분석
- 자기소개서
- 퀀트
- 하이퍼 파라미터
- Today
- Total
GIL's LAB
지도학습에서의 데이터 분할과 k겹 교차 검증 본문
지도학습 모델을 만들 때 데이터를 나눠야하고 k겹 교차 검증을 해야한다 등의 내용은 알지만, 왜 해야하고 어떻게 해야 하는지를 모르는 분이 많은 것 같습니다.
그래서 이번 포스팅에서는 지도학습에서 왜 학습 데이터와 평가 데이터를 나눠야 하는지, k겹 교차 검증은 왜 사용해야 하는지 등에 대해 정리해보겠습니다.
학습 데이터와 평가 데이터
학습에 사용한 데이터를 사용하여 모델을 평가하면 적절하게 적합된 모델보다 과적합된 모델을 좋게 평가하는 문제가 발생합니다. 따라서 아래 그림과 같이 모델을 학습하는데 사용하는 학습 데이터와 학습된 모델을 평가하는데 사용할 평가 데이터로 분할해야 합니다.

위 그림에서 보듯이, 데이터를 학습 데이터와 평가 데이터로 임의로 분할합니다. 정해진 비율은 없으나 통상적으로 6:4 혹은 7:3 정도의 비율이 되도록 나눕니다. 이때 중요한 점은 평가 데이터는 관측하지 않았다고 간주해야 하고 데이터를 분리할 때 특정한 기준이 있어서는 안 됩니다. 다시 말해, 객관적인 모델 평가를 위해 평가 데이터는 탐색, 전처리, 파라미터 추정 등 모델을 학습하는 전 과정에서 활용해서는 안됩니다. 전체 데이터를 탐색하기도 하지만, 원칙적으로는 분할해야 합니다. 학습 데이터로 학습한 모델을 평가 데이터의 특징에 적용하여 예측 결과를 뽑아내고, 이 결과와 실제 라벨을 비교하여 모델을 평가합니다.
k겹 교차 검증
그런데 위에서 설명한 방법은 두 가지의 문제점이 있습니다. 첫 번째 문제점은 평가 데이터는 모델 학습에 전혀 기여하지 못했다는 점입니다. 데이터 크기가 작을수록 이렇게 버리는 데이터가 아깝게 느껴집니다. 학습에 사용할 샘플이 많을수록 일반화 능력이 뛰어난 모델을 학습할 가능성이 크기 때문입니다. 두 번째 문제점은 아무리 데이터를 임의로 분할했더라도 평가 결과가 객관적이지 않을 수 있다는 점입니다. 위 문단에서 객관성 확보를 위해 학습 데이터와 평가 데이터를 분할했다고 했는데, 왜 객관적이지 않다고 하는 것일까요? 그 이유는 모델이 평가 데이터에 과적합될 위험이 있기 때문입니다. 즉, 일반적으로 여러 개의 모델을 학습하여 평가 결과를 바탕으로 모델을 비교하는데, 수 많은 모델을 비교하다보면 평가 데이터에만 적합한 모델을 최종 모델로 선정할 가능성이 큽니다.
더욱 객관적인 평가가 필요할 때 쓰는 기법으로 k겹 교차 검증이 있습니다. k겹 교차 검증은 데이터를 k개의 작은 데이터(부분 집합)로 분할한 뒤, 각각의 작은 데이터를 평가 데이터로 사용하고 나머지 데이터를 학습 데이터로 사용하여 모델을 평가하는 방식입니다. k를 5로 했을 때의 예시를 아래 그림을 통해 살펴보겠습니다.
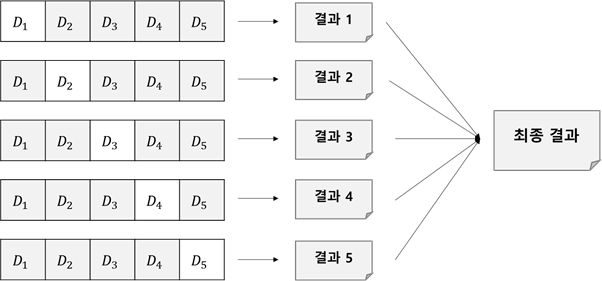
위 그림에서 전체 데이터는 부분 집합 D1 , D2 , D3 , D4 , D5 로 분할됐습니다. 또한, D1 을 제외한 데이터로 모델을 학습하고 D1 으로 평가한 결과부터 D5 을 제외한 데이터로 모델을 학습하고 D5 로 평가한 결과를 종합하여 해당 모델을 최종적으로 평가합니다. 종합할 때는 평균, 중위수, 최솟값, 최댓값 등을 사용합니다.
그런데 k겹 교차 검증을 하는 과정에서 k개의 모델을 학습하게 되는데 어느 모델을 사용해야 할까요? 만약 k개 모델 중 하나를 고른다면, 앞서 설명한 학습 데이터와 평가 데이터를 분리할 때의 첫 번째 문제점인 평가 데이터를 버린다는 문제가 해결되지 않게 됩니다. 따라서 최종 결과가 만족스러운 모델에 대해서 전체 데이터를 가지고 재학습하는 것이 바람직합니다.
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| 랜덤포레스트와 다중공선성 (0) | 2022.07.24 |
|---|---|
| 머신러닝 파이프라인 (Machine Learning Pipeline) (5) | 2022.03.17 |
| [AutoML] 채용 동향 (0) | 2022.03.01 |
| [AutoML] 머신러닝 자동화가 필요한 이유 (0) | 2022.02.27 |
| [AutoML] AutoML이란 무엇인가? (0) | 2022.02.18 |
