
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 머신러닝
- 데이터사이언티스트
- 퀀트 투자 책
- 퀀트
- 코딩테스트
- 하이퍼 파라미터
- 데이터 분석
- 데이터사이언스
- 주요 파라미터
- 과제전형
- 데이터분석
- 대학원
- 사이킷런
- 이력서 첨삭
- AutoML
- 주식데이터
- 공공데이터
- 데이터 사이언스
- 주가데이터
- 파이썬
- 랜덤포레스트
- pandas
- 경력 기술서
- sklearn
- 자기소개서
- 데이터 사이언티스트
- 커리어전환
- 판다스
- 하이퍼 파라미터 튜닝
- 경력기술서 첨삭
- Today
- Total
GIL's LAB
반복측정 분산분석과 그리드 서치: 가장 중요한 파라미터 찾기 본문
이번 포스팅에서는 여러 파라미터 가운데 반응 변수에 가장 큰 영향을 주는 파라미터를 찾는 방법에 대해 알아보겠습니다.
문제 상황
다음과 같이 파라미터 x1, x2, x3가 있고, 파라미터 값에 따른 반응 변수 y가 있다고 하겠습니다.
| 행 번호 | x1 | x2 | x3 | y |
| 1 | 1 | a | 5 | 10 |
| 2 | 1 | a | 10 | 10 |
| 3 | 1 | b | 5 | 20 |
| 4 | 1 | b | 10 | 20 |
| 5 | 2 | a | 5 | 25 |
| 6 | 2 | a | 10 | 30 |
| 7 | 2 | b | 5 | 10 |
| 8 | 2 | b | 10 | 15 |
| 9 | 3 | a | 5 | 20 |
| 10 | 3 | a | 10 | 10 |
| 11 | 3 | b | 5 | 30 |
| 12 | 3 | b | 10 | 40 |
x1은 {1, 2, 3}, x2는 {a, b}, x3은 {5, 10}을 순회하면서 설정했고, 그에 따른 y가 있는 것을 알 수 있습니다.
이 데이터에서 궁금한 것은 y에 가장 큰 영향을 끼치는 파라미터는 x1, x2, x3 가운데 어떤 것인지 판단하는 것입니다. 아래 내용을 읽어보기 전에 어떻게 하면 가장 중요한 파라미터를 선정할 수 있을지 생각해보시기 바랍니다.
반복측정 분산분석
위 문제를 해결하는데 사용할 수 있는 통계적 기법은 대응표본 t검정 혹은 반복측정 분산분석입니다. 대응표본 t검정과 반복측정 분산분석 모두 같은 실험체에 대해 특정 조치를 했을 때와 하지 않았을 때를 비교하는 통계적인 방법입니다. 차이가 있다면 대응표본 t검정은 조치 전 / 조치 후라는 두 개의 클래스만 비교하지만, 반복측정 분산분석은 조치 전 / 조치 후 / 조치 후 오랜 시간 지난 후 등 셋 이상의 클래스를 비교하는데 사용할 수 있습니다.
아래 간단한 예제를 살펴보겠습니다.
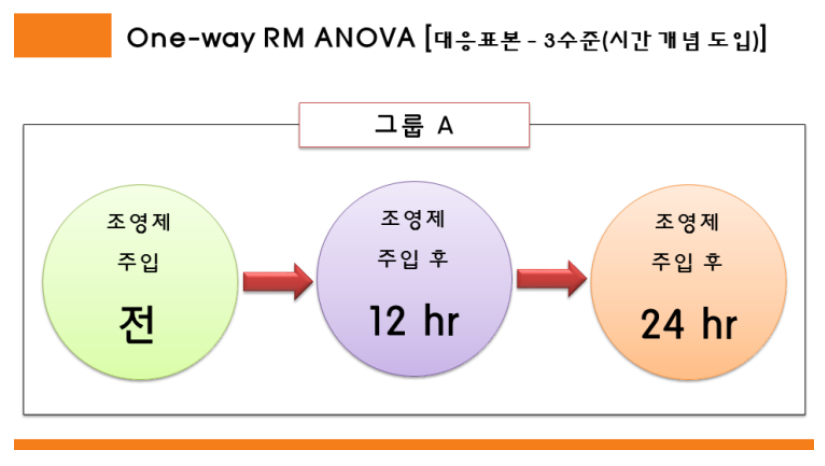
환자 a, b, c가 있고 조영제 주입 전 / 주입 후 12시간 경과 / 주입 후 24시간 경과를 비교한다고 하겠습니다. 수학적인 내용을 제외하고 어떤 값끼리 비교되는지만 다음 데이터를 통해 알아보겠습니다.
| 환자 | 주입 전 | 주입 후 12시간 경과 | 주입 후 24시간 경과 |
| a | a0 | a1 | a2 |
| b | b0 | b1 | b2 |
| c | c0 | c1 | c2 |
위 데이터에서 a0, a1, a2가 서로 비교되고, b0, b1, b2가 서로 비교되고, c0, c1, c2가 서로 비교됩니다. 즉, 같은 환자에 대한 값이 서로 비교됩니다. 다시 말해, 주입 전과 후라는 조건을 제외한 나머지 조건을 통제하기 위해 다른 환자에 대해서는 비교하지 않습니다.
자세한 내용은 이 블로그를 참고하시기 바랍니다.
이 내용을 우리가 풀고자 하는 문제와 연결해보겠습니다. x1의 중요도를 측정하려면, x1을 달리했을 때의 반응 변수를 비교해야 합니다. 그런데 이때 x2와 x3도 같이 변하면 x1의 효과를 측정하기 어렵습니다. 따라서 다음과 같이 비교 대상을 설정할 수 있습니다.
- (x2 = a, x3 = 5)인 그룹의 비교: 행 번호 (1, 5, 9)
- (x2 = a, x3 = 10)인 그룹의 비교: 행 번호 (2, 6, 10)
- (x2 = b, x3 = 5)인 그룹의 비교: 행 번호 (3, 7, 11)
- (x2 = b, x3 = 10)인 그룹의 비교: 행 번호 (4, 8, 12)
사실 자세한 수식을 몰라도 위 내용만 이해하면 중요한 변수를 찾을 수 있습니다. 계산은 소프트웨어가 해주니까요!
파이썬을 이용한 반복측정 분산분석
statsmodels 패키지의 AnovaRM을 사용하면 반복측정 분산분석을 손쉽게 수행할 수 있습니다. 1, 2, 3이라는 세 개의 실험체가 있고, 실험 조건은 a, b, c, 실험 결과는 output으로 정리되어 있는 예제를 통해 살펴보겠습니다.
# AnovaRM 사용 방법: 인풋에 따라 아웃풋 변동이 없을 때
import pandas as pd
from statsmodels.stats.anova import AnovaRM
data = pd.DataFrame({"sub_id":[1,2,3,1,2,3,1,2,3],
"output":[10,20,30,10,20,30,10,20,30],
"input":["a", "a", "a", "b", "b", "b", "c", "c", "c"]})
display(data)
aovrm = AnovaRM(data, 'output', 'sub_id', within=['input'])
res = aovrm.fit()
print(res)[실행 결과]

AnovaRM 함수의 입력으로 사용되는 데이터의 구조와 함수 사용 구조를 알아두시기 바랍니다. 즉, 데이터 구조는 실험체를 식별할 수 있는 ID, 반응 변수 값, 조건 변수로 구성되어야 하며, AnovaRM 함수의 입력은 순서대로 데이터프레임, 반응 변수를 나타내는 컬럼명, 실험체 ID를 나타내는 컬럼명입니다.
결과를 보면 p-value가 1인 것을 알 수 있는데, 그 이유는 조건에 관계없이 반응 변수가 변하지 않았기 때문입니다. 다시 말해, sub_id가 1인 샘플을 보면, input이 a, b, c일때 모두 10이고, sub_id가 2인 샘플은 모두 20, 3인 샘플은 모두 30입니다.
다른 데이터 예제를 살펴보겠습니다.
# AnovaRM 사용 방법: 인풋에 따라 아웃풋이 증가할 때
data = pd.DataFrame({"sub_id":[1,2,3,1,2,3,1,2,3],
"output":[10,20,30,20,40,60,30,60,90],
"input":["a", "a", "a", "b", "b", "b", "c", "c", "c"]})
display(data)
aovrm = AnovaRM(data, 'output', 'sub_id', within=['input'])
res = aovrm.fit()
print(res)
이번에는 p-value가 0.05미만으로 유의하다고 할 수 있는데, 그 이유는 input에 따라 output이 크게 변동하기 때문입니다.
예제: 그리드 서치 결과에서 가장 중요한 파라미터 파악
이번에는 머신러닝의 그리드 서치 결과에서 가장 중요한 파라미터를 찾는 현실적인 예제를 살펴보겠습니다. 먼저, 실험 데이터를 sklearn에서 제공하는 boston 데이터 셋을 학습 데이터와 평가 데이터로 나누는 방식으로 준비합니다.
# 데이터 준비
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
X, Y = load_boston(return_X_y=True)
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y, random_state = 41)Lasso 모델의 alpha, maxiter, tol이라는 파라미터를 튜닝해보겠습니다. 그리드 서치에 대한 내용은 이전 포스팅를 참고하기 바랍니다.
# 그리드 서치
from sklearn.linear_model import Lasso
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import mean_absolute_error as MAE
grid = ParameterGrid({"alpha": [0.1, 1, 10],
"max_iter":[100, 1000, 10000],
"tol":[1e-5, 1e-4, 1e-3]})
score_list = []
for parameter in grid:
model = Lasso(**parameter).fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
score = MAE(Test_Y, pred_Y)
score_list.append(score)그리드 서치 결과를 데이터프레임으로 정리하겠습니다.
# 그리드 서치 결과 정리
result = pd.DataFrame(grid)
result["score"] = score_list
display(result.head(10))
이제 위 데이터에 AnovaRM 함수를 적용하여 alpha의 중요도를 측정해보겠습니다. 먼저 ID를 부여할 수 있도록 alpha를 기준으로 정렬하고 alpha와 score 컬럼만 가져옵니다. 이때, alpha를 제외한 나머지 변수로도 정렬해야 ID 부여가 꼬이지 않습니다. 그 다음으로 alpha를 제외한 다른 값이 같으면 같은 ID를 갖도록 다음과 같이 ID를 부여합니다.
# 데이터 정리: alpha 예시
result_ANOVA = result.sort_values(by = ["alpha", "max_iter", "tol"])
num_unique = len(result_ANOVA["alpha"].unique())
result_ANOVA['subject_ID'] = list(range(int(len(result_ANOVA) / num_unique))) * num_unique
display(result_ANOVA)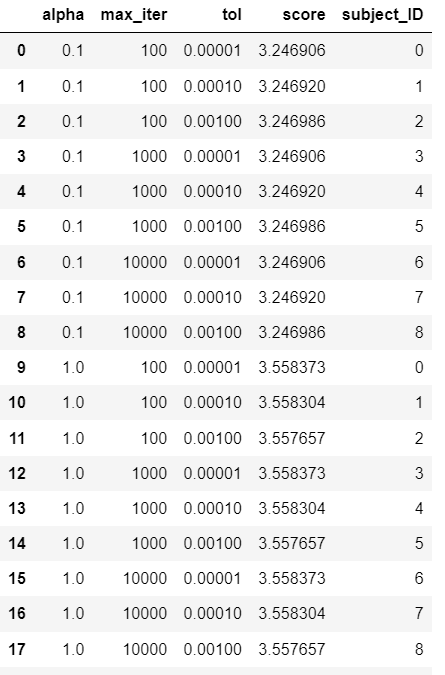
결과를 보면 정렬을 했기에 인덱스가 0과 9인 행의 나머지 파라미터(max_iter, tol)가 같고 subject_ID가 같음을 알 수 있습니다. 즉, subject_ID가 같으면 alpha를 제외한 나머지 조건이 동일함을 알 수 있습니다.
데이터가 준비되었으니, AnovaRM을 통해 중요도를 측정해보겠습니다.
aovrm = AnovaRM(result_ANOVA, 'score', 'subject_ID', within=['alpha'])
res = aovrm.fit()
print(res)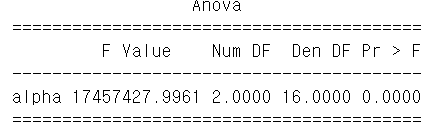
p-value가 0.0000으로 유효한 영향을 끼침을 알 수 있습니다.
이젠 전체 파라미터에 대해 적용해보겠습니다.
# 전체 파라미터에 적용
parameter_list = ["alpha", "max_iter", "tol"]
for parameter in parameter_list:
sort_order = sorted(parameter_list, key = lambda x:x!=parameter)
result_ANOVA = result.sort_values(by = sort_order)
num_unique = len(result_ANOVA[parameter].unique())
result_ANOVA['subject_ID'] = list(range(int(len(result_ANOVA) / num_unique))) * num_unique
aovrm = AnovaRM(result_ANOVA, 'score', 'subject_ID', within=[parameter])
res = aovrm.fit()
print(parameter)
print(res)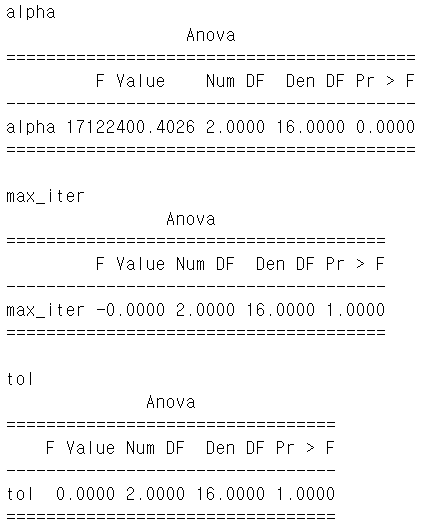
F value가 가장 큰 (P-value가 가장 작은) alpha가 가장 중요함을 알 수 있습니다.
위 코드에서 sort_order는 현재 파라미터를 맨 앞으로 오도록 정렬한 파라미터 목록입니다.
여기서 사용한 전체 코드는 아래에서 다운로드받을 수 있습니다.
'데이터사이언스 > 확률 통계' 카테고리의 다른 글
| 로또 추천이 말도 안되는 이유 (feat data) (0) | 2023.08.01 |
|---|---|
| scipy를 이용한 확률 분포 샘플링 (0) | 2022.08.14 |

