
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 데이터사이언스
- 주식데이터
- 데이터분석
- 데이터 사이언스
- 공공데이터
- 하이퍼 파라미터
- AutoML
- 코딩테스트
- 과제전형
- 데이터사이언티스트
- 이력서 첨삭
- pandas
- 자기소개서
- 주가데이터
- 경력 기술서
- 사이킷런
- 퀀트 투자 책
- sklearn
- 파이썬
- 대학원
- 커리어전환
- 랜덤포레스트
- 퀀트
- 하이퍼 파라미터 튜닝
- 데이터 사이언티스트
- 데이터 분석
- 머신러닝
- 주요 파라미터
- 경력기술서 첨삭
- 판다스
Archives
- Today
- Total
GIL's LAB
[생각해볼 거리] 파라미터 최적화 문제와 그럴싸한 함수 본문
회사 일과 집필로 바빠서 오랜만에 포스팅입니다.
오늘 포스팅에서는 현업에서 굉장히 자주 맞닥뜨리는 문제인데 교과서에서는 다룰 수 없는 문제에 대해 이야기해보겠습니다.
파라미터 최적화 문제
먼저, 파라미터 최적화 문제는 어떤 성능을 최대화할 수 있는 파라미터를 설정하는 문제입니다.
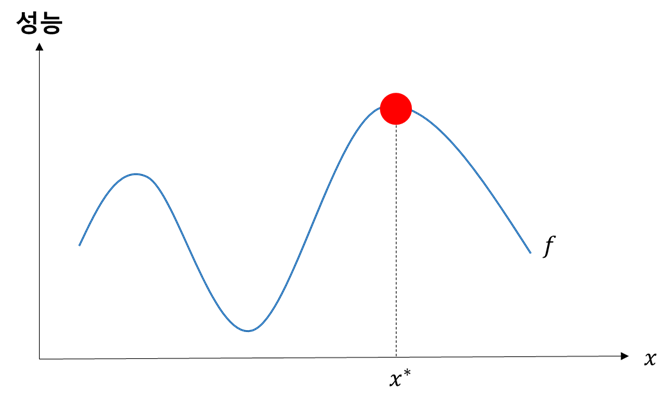
위 그림에서 x축이 파라미터이고 y축이 성능을 나타냅니다. 즉, 우리의 목표는 성능을 최대화하는 x*를 찾는 것입니다. 이 문제는 다음과 같은 간단한 수리 모형으로 표현할 수 있습니다.

제약이 없어서 함수 f가 어지간히 복잡하지 않는한 해를 구하기 어려운 문제가 아닙니다. 이러한 문제는 머신러닝의 하이퍼 파라미터 튜닝뿐만 아니라, 다양한 분야에서 발생합니다. 예를 들어, 제조 분야에서는 “수율을 최대화 혹은 불량을 최소화하는 생산 조건 파악”하는 문제를, 홍보/마케팅 분야에서는 수익을 최대화할 수 있는 광고 비용을 추정하는 문제가 있습니다.
파라미터 최적화 문제가 어려운 이유
일반적인 최적화 문제보다 어려운 점은 목적이 되는 함수를 정확히 알 수 없기에, 최적화 방법론을 적용할 수 없다는 것입니다. 따라서 아래 그림과 같이 데이터를 바탕으로 함수를 추정하고 이 함수의 최대 혹은 최소값을 찾아야 합니다.

설명을 위해서 함수 f를 점선으로 표시하고 데이터를 까만색 점(a, b, c)으로 표시했습니다.
사실 위 상황처럼 데이터가 세 개에 불과한 경우는 드물지만, 데이터를 얻기가 어려운 것은 사실입니다. 이전 그림처럼 모든 가능한 경우의 수의 데이터가 다 있다면 코드 몇 줄로 최적의 파라미터를 찾을 수 있지만, 실제로는 우리가 원하는 데이터를 손쉽게 얻을 수 없습니다. 다양한 조건에서의 데이터를 얻기 위한 목적으로 퍼포먼스가 좋지 않을 것이라 예상되는 조건의 실험을 하는 곳은 단언컨대 없을 겁니다. 쉽게 예를 들어, A/B 테스트를 할 때 확실히 안 좋을 것이라 예상되는 화면(예: 모든 화면을 새까맣게 설정하기)은 테스트하지 않습니다. 자칫했다가 새까만 화면만 본 고객이 이탈할 수 있으니까요.
다시 세 개의 데이터 포인트만 있는 그림으로 돌아오겠습니다. 파란색 점선은 안 보인다고 가정하겠습니다. 이 상황에서 우리는 성능을 최대화하는 x를 찾고 싶습니다. 그러면 아래 보기 중에 어느 x를 사용하는 것이 좋을까요?
1번. a
2번. b
3번. c
가장 멍청한 대답은 1번이나 2번일 것입니다. 이미 3번보다 좋지 않다는 것이 밝혀졌으니까요. 그러면 2번은 좋은 대답일까요? 이것도 역시 좋은 대답은 아닙니다. 현업과 일하는데 그저 결과만 읊어주는 데이터 사이언티스트는 좀 심하게 이야기해서 아무 쓸모가 없습니다. 정답을 이야기하면 "알 수 없다"입니다. a, b, c만 가지고 함수 f를 피팅하는 것은 불가능할 겁니다. 이번에는 정답을 알 수 없다라고 이야기하는 데이터 사이언티스트가 되었습니다. 역시 현업에서는 쓸모없다고 생각할 가능성이 높습니다.
함수 근사하기
이제부터 생각해야하는 것은 그럴싸함입니다. 겨우 세 개의 데이터로 경향성을 아는 것은 보통 불가능합니다. 데이터가 많으면 조금은 낫겠지만, 상황이 확 좋아지진 않을 겁니다 (통상 데이터 대비 추정할 파라미터가 너무 많습니다). 그러면 그럴싸하게 c에서 가장 값이 크니, 그 근방을 찾아보는 것이 좋지 않을까요? 라고 이야기할 수 있습니다. 그래서 c보다 큰 구간에 현업을 졸라서 2개의 포인트 d와 e를 더 얻어 다음과 같은 함수 f를 g로 피팅했다고 합시다.

실제 함수인 파란색과는 다르지만 나름(?) 비슷해졌습니다. 이제 더 이상 데이터를 모을 수 없는 상황이라면 g를 최대화하는 일반적인 최적화 문제가 되었습니다.

결론적으로는 데이터를 바탕으로 함수를 피팅하고 이 함수를 최대화하는 문제의 최적해를 구하면 되는구나라고 생각할 수도 있습니다. 여기서 가장 중요한 점은 이 함수가 그럴싸해야 한다는 것입니다. 저 다섯개 포인트를 통과하는 함수는 무한히 많습니다. 포인트가 엄청나게 많더라도 모든 포인트를 지나는 함수 역시 무한히 많습니다. 즉, 실제로는 c와 d사이에서 최댓값이 있지만, 근사하는 과정에서 d가 최댓값인 것처럼 되었습니다.
매우 중요한 사실은 데이터 분석의 목적은 주어진 데이터를 바탕으로 일반화하는 것이며, 데이터 양이 적거나 편향되면 일반화할 수 없다는 것입니다. 위 예시에서 데이터가 무한히 주어지지 않는 한 파란색 곡선은 완벽히 피팅할 수 없을 것입니다. 실제로 파라미터는 여러 개인데 데이터는 많지 않은 경우가 흔합니다.
그래서 이 문제(엄밀히 말하자면 데이터 기반의 모든 문제가 이러합니다)는 제가 강조드리고 싶은 부분은 주어진 데이터만으로는 완벽히 해결할 수 없고, 데이터의 도메인을 잘 아는 전문가와 협업해야 합니다. 대표적인 방법으로 데이터에 기반한 함수를 여러 개 피팅해서 도메인 전문가와 그 결과를 가지고 논의하는 것입니다.
저도 뽕(?)이 차오르던 박사과정 초년차에는 데이터만 주면 어떤 문제든 해결할 수 있다 생각하던 사람이었지만, 더 성숙해질수록 고개를 숙이게 됩니다. 데이터만 가지고 할 수 있는 일은 생각보다 많지 않습니다.
앞으로도 이런 생각해볼만한거리나 현업에서의 이슈 등을 다뤄보겠습니다. 데이터사이언스 분야의 면접을 준비하는 취업준비생한테 크게 도움이 될 것 같네요 :)
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| [AutoML] 머신러닝 자동화가 필요한 이유 (0) | 2022.02.27 |
|---|---|
| [AutoML] AutoML이란 무엇인가? (0) | 2022.02.18 |
| 모델 성능 향상을 위한 하이퍼 파라미터 튜닝 (0) | 2021.09.04 |
| 클래스 불균형 문제 (2) 탐색 방법 (0) | 2021.09.02 |
| 클래스 불균형 문제 (1) 문제 정의 (0) | 2021.09.02 |
'데이터사이언스/머신러닝' Related Articles
more



Comments