
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 머신러닝
- 데이터 사이언스
- 주식데이터
- 판다스
- 퀀트 투자 책
- 과제전형
- 퀀트
- 경력 기술서
- 하이퍼 파라미터
- 파이썬
- pandas
- 랜덤포레스트
- 사이킷런
- 주요 파라미터
- 이력서 첨삭
- 대학원
- AutoML
- 데이터사이언스
- 커리어전환
- 데이터분석
- 데이터사이언스학과
- sklearn
- 데이터사이언티스트
- 경력기술서 첨삭
- 코딩테스트
- 데이터 분석
- 자기소개서
- 주가데이터
- 하이퍼 파라미터 튜닝
- 데이터 사이언티스트
- Today
- Total
GIL's LAB
아파트매매 실거래 데이터 수집 본문
이번 포스팅에서는 국토교통부에서 제공하는 아파트매매 실거래 데이터를 수집하는 방법에 대해 알아보겠습니다.
데이터 출처는 다음과 같습니다.
https://www.data.go.kr/data/15057511/openapi.do
국토교통부_아파트매매 실거래 상세 자료
부동산 거래신고에 관한 법률에 따라 신고된 주택의 실거래 자료를 제공
www.data.go.kr
서비스키 발급
데이터를 수집하기 위해서는 서비스키를 먼저 발급받아야 합니다.
위의 링크에 접속해서 중간쯤에 있는 "활용 신청" 버튼을 클릭합니다.

그러면 다음과 같이 공공데이터포털에 로그인하라는 메시지가 뜹니다.

확인버튼을 누르고 공공데이터포털에 로그인해줍니다.
ID가 없다면 회원가입을 하도록 합니다.
활용 신청을 하고 나면, 마이페이지 > 오픈API > 개발계정에서 아래 그림의 빨간 박스처럼 인증키를 확인할 수 있습니다.
참고로 서비스키는 발급받은 후 1시간 후에 사용이 가능합니다.
데이터 수집
데이터는 제공한 샘플 코드를 참고하면 쉽게 수집할 수 있습니다. 이 부분은 입출력을 확인한 뒤에 다시 살펴보겠습니다.
기술문서에 따르면 입력 파라미터로 전달해야 하는 값은 다음과 같습니다.
| 항목명(영문) | 항목명(국문) | 항목설명 |
| serviceKey | 인증키 | 공공데이터포털에서 발급받은 인증키 |
| pageNo | 페이지번호 | 페이지번호 |
| numOfRows | 한 페이지 결과 수 | 한 페이지 결과 수 |
| LAWD_CD | 지역코드 | 각 지역별 코드 행정표준코드관리시스템(www.code.go.kr)의 법정동코드 10자리 중 앞 5자리 |
| DEAL_YMD | 계약월 | 실거래 자료의 계약년월(6자리) |
여기서 법정동코드목록은 https://www.code.go.kr/stdcode/regCodeL.do에서 확인할 수 있습니다.
API가 반환하는 항목은 다음과 같습니다. 이 항목에서 필요한 부분만 가져와서 정리할 것입니다.
여기서는 년, 월, 아파트, 전용면적, 거래 금액만 가져오겠습니다.
또한, totalCount를 참고하여 전체 데이터를 가져오는 코드를 만들어보겠습니다.
| 항목명(영문) | 항목명(국문) | 항목설명 | 샘플데이터 |
| resultCode | 결과코드 | 결과코드 | 00 |
| resultMsg | 결과메세지 | 결과메세지 | NORMAL SERVICE. |
| numOfRows | 한 페이지 결과 수 | 한 페이지 결과 수 | 10 |
| pageNo | 페이지 번호 | 페이지 번호 | 1 |
| totalCount | 전체 결과 수 | 전체 결과 수 | 3 |
| Deal Amount | 거래금액 | 거래금액(만원) | 82,500 |
| Build Year | 건축년도 | 건축년도 | 2008 |
| Deal Year | 년 | 계약년도 | 2015 |
| Road Name | 도로명 | 도로명 | 사직로8길 |
| Road Name Bonbun | 도로명건물본번호코드 | 도로명건물본번 | 00004 |
| Road Name Bubun | 도로명건물부번호코드 | 도로명건물부번 | 00000 |
| Road Name Sigungu Code | 도로명시군구코드 | 도로명시군구코드 | 11110 |
| Road Name Seq | 도로명일련번호코드 | 도로명코드 | 03 |
| Road Name Basement Code | 도로명지상지하코드 | 도로명지상지하코드 | 0 |
| Road Name Code | 도로명코드 | 도로명코드 | 4100135 |
| Dong | 법정동 | 법정동 | 사직동 |
| Bonbun | 법정동본번코드 | 법정동본번코드 | 0009 |
| Bubun | 법정동부번코드 | 법정동부번코드 | 0000 |
| Sigungu Code | 법정동시군구코드 | 대상물건의 시군구코드 | 11110 |
| Eubmyundong Code | 법정동읍면동코드 | 대상물건의 읍면동코드 | 11500 |
| Land Code | 법정동지번코드 | 법정동지번코드 | 1 |
| Apartment Name | 아파트 | 아파트명 | 광화문풍림스페이스본(9-0) |
| Deal Month | 월 | 계약월 | 12 |
| Deal Day | 일 | 일 | 1 |
| 일련번호 | 일련번호 | 일련번호 | 11110-2203 |
| Area for Exclusive Use | 전용면적 | 전용면적(㎡) | 94.51 |
| Jibun | 지번 | 지번 | 9 |
| Regional Code | 지역코드 | 지역코드 | 11110 |
| Floor | 층 | 층 | 11 |
| Cancel Deal Type | 해제여부 | 해제여부 | O |
| Cancel Deal Day | 해제사유발생일 | 해제사유발생일 | 21.01.27 |
| REQ GBN | 거래유형 | 중개 및 직거래 여부 | 중개거래 |
| Rdealer Lawdnm | 중개업소주소 | 시군구 단위 | 서울 서초구 |
한 페이지 데이터 수집
import requests
my_key = ''
url = 'http://openapi.molit.go.kr/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/getRTMSDataSvcAptTradeDev'
params ={'serviceKey' : my_key, 'pageNo' : '1', 'numOfRows' : '10', 'LAWD_CD' : '41450', 'DEAL_YMD' : '202210' }
response = requests.get(url, params=params)response 객체에 저장된 텍스트 일부를 확인해보겠습니다.
print(response.text[:1000])[실행 결과]
<?xml version="1.0" encoding="UTF-8" standalone="yes"?><response><header><resultCode>00</resultCode><resultMsg>NORMAL SERVICE.</resultMsg></header><body><items><item><거래금액> 94,900</거래금액><거래유형>중개거래</거래유형><건축년도>2017</건축년도><년>2022</년><도로명>하남유니온로</도로명><도로명건물본번호코드>00070</도로명건물본번호코드><도로명건물부번호코드>00000</도로명건물부번호코드><도로명시군구코드>41450</도로명시군구코드><도로명일련번호코드>00</도로명일련번호코드><도로명코드>3351193</도로명코드><법정동> 신장동</법정동><법정동본번코드>0602</법정동본번코드><법정동부번코드>0000</법정동부번코드><법정동시군구코드>41450</법정동시군구코드><법정동읍면동코드>10600</법정동읍면동코드><법정동지번코드>1</법정동지번코드><아파트>하남유니온시티에일린의뜰</아파트><월>10</월><일>2</일><일련번호>41450-354</일련번호><전용면적>84.99</전용면적><중개사소재지>경기 하남시</중개사소재지><지번>602</지번><지역코드>41450</지역코드><층>21</층><해제사유발생일> </해제사유발생일><해제여부> </해제여부></item><item><거래금액> 66,000</거래금액><거래유형>직거래</거래유형><건축년도>2018</건축년도><년>2022</년><도로명>하남유니온로</도로명><도로명건물본번호코드>00030</도로명건물본번호코드><도로명건물부번호코드>00000</도로명건물부번호코드><도로명시군구코드>41450</도로명시군구코드><도로명일련번호코드>00</도로명일련번호코드><도로명지상지하코드>0</도로명지상지하코드><도로명코드>3351193</도로명코드><법정동> 신장동</법정동><법정동본번코드>0593</법정동본번코드><법정동부번코드>0000</텍스트로 되어 있다보니 우리가 원하는 값만 가져오기가 어렵습니다. 따라서 BeautifulSoup을 이용해서 파싱하겠습니다.
from bs4 import BeautifulSoup as BS
soup = BS(response.text, 'xml')
item = soup.find('item')
print(item)<item><거래금액> 94,900</거래금액><거래유형>중개거래</거래유형><건축년도>2017</건축년도><년>2022</년><도로명>하남유니온로</도로명><도로명건물본번호코드>00070</도로명건물본번호코드><도로명건물부번호코드>00000</도로명건물부번호코드><도로명시군구코드>41450</도로명시군구코드><도로명일련번호코드>00</도로명일련번호코드><도로명코드>3351193</도로명코드><법정동> 신장동</법정동><법정동본번코드>0602</법정동본번코드><법정동부번코드>0000</법정동부번코드><법정동시군구코드>41450</법정동시군구코드><법정동읍면동코드>10600</법정동읍면동코드><법정동지번코드>1</법정동지번코드><아파트>하남유니온시티에일린의뜰</아파트><월>10</월><일>2</일><일련번호>41450-354</일련번호><전용면적>84.99</전용면적><중개사소재지>경기 하남시</중개사소재지><지번>602</지번><지역코드>41450</지역코드><층>21</층><해제사유발생일> </해제사유발생일><해제여부> </해제여부></item>find 메서드는 특정 태그의 첫 번째 값을 가져오는데 사용합니다. 즉, 위 코드는 받아온 데이터의 첫 번째 아이템 태그를 출력한 것이라 할 수 있습니다.
이 태그에서 필요한 정보를 다음과 같이 가져오겠습니다.
item = soup.find('item')
print(item.find('거래금액').text)
print(item.find('아파트').text)
print(item.find('년').text)
print(item.find('월').text)
print(item.find('전용면적').text)[실행 결과]
94,900
하남유니온시티에일린의뜰
2022
10
84.99이제 현재 페이지에 있는 모든 아이템에 접근해서 데이터를 가져와보겠습니다. 이때 사용할 수 있는 메서드는 find_all입니다. 이 메서드는 검색한 모든 태그를 가져옵니다.
for item in soup.find_all('item'):
print(item.find('거래금액').text)
print(item.find('아파트').text)
print(item.find('년').text)
print(item.find('월').text)
print(item.find('전용면적').text)
print("\n")[실행 결과]
94,900
하남유니온시티에일린의뜰
2022
10
84.99
66,000
하남유시티대명루첸리버파크
2022
10
74.34
15,950
대동피렌체
2022
10
32.004
40,000
한승미메이드
2022
10
84.83
83,000
하남풍산아이파크(5단지)
2022
10
84.966
76,500
미사강변 센텀팰리스
2022
10
74.86
80,000
미사강변파밀리에
2022
10
59.96
80,000
미사강변사랑으로부영아파트
2022
10
84.9786
78,500
미사강변사랑으로부영아파트
2022
10
84.9786
73,000
미사강변사랑으로부영아파트
2022
10
84.9918전체 페이지 데이터 수집
한 페이지 데이터 수집 코드를 확장하여 전체 페이지 데이터를 수집하는 코드를 만들어보겠습니다.
전체 페이지 수는 totalCount를 바탕으로 계산할 수 있습니다.
print(soup.find('totalCount').text)[실행 결과]
36총 36개의 아이템이 있고 페이지마다 10개의 아이템이 있으므로 총 4개의 페이지가 있음을 알 수 있습니다. 현재 페이지를 제외하면 3개 페이지가 있겠네요.
아니면 데이터가 없을 때까지 요청하는 것도 방법입니다. 여기서는 데이터가 없을 때까지 요청해보겠습니다.
data = []
pageNo = 1
while True:
params ={'serviceKey' : my_key, 'pageNo' : str(pageNo), 'numOfRows' : '10', 'LAWD_CD' : '41450', 'DEAL_YMD' : '202210' }
response = requests.get(url, params=params)
soup = BS(response.text, 'xml')
if len(soup.find_all('item')) == 0:
break
for item in soup.find_all('item'):
record = []
record.append(item.find('거래금액').text)
record.append(item.find('아파트').text)
record.append(item.find('년').text)
record.append(item.find('월').text)
record.append(item.find('전용면적').text)
data.append(record)
pageNo += 1pageNo를 1로 한 뒤, soup.find_all('item')의 크기가 0일 때까지 데이터를 요청하고 크기가 0이 아니면 pageNo를 1만큼 증가시키는 것입니다. 또한, 거래 금액, 아파트, 년, 월, 전용면적을 갖는 record를 data에 추가하는 방식으로 데이터를 저장합니다.
이렇게 저장한 nested list를 데이터프레임으로 변환하겠습니다.
import pandas as pd
data = pd.DataFrame(data, columns = ["가격", "아파트", "연도", "월", "전용면적"])
data['가격'] = data['가격'].str.lstrip().str.replace(',', '').astype(int)
data[['연도', '월']] = data[['연도', '월']].astype(int)
data['전용면적'] = data['전용면적'].astype(float)가격에 포함된 공백, 콤마를 제거하고 적절한 자료형(int와 float)으로 변환했습니다.
저장한 데이터를 확인해보겠습니다.
data.head()[실행 결과]
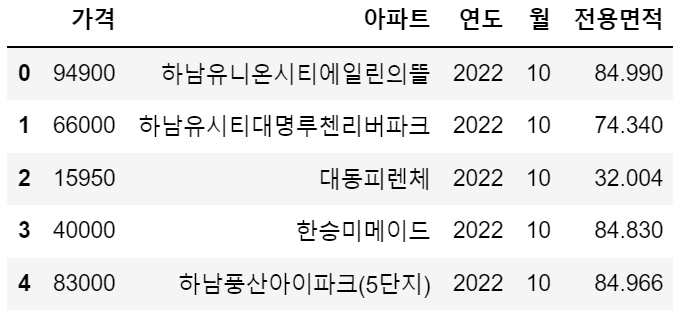
특정 기간
이번에는 특정 기간의 데이터를 수집해보겠습니다. 기간은 2020년 10월부터 2022년 10월까지로 해보겠습니다. 이 코드를 응용하면 다른 지역 데이터까지 수집이 가능합니다.
data = []
year = 2020
month = 10
while True:
print(year, month)
if (year == 2022) and (month == 10):
break
YMD = str(year) + str(month).zfill(2)
pageNo = 1
while True:
params ={'serviceKey' : my_key, 'pageNo' : str(pageNo), 'numOfRows' : '10', 'LAWD_CD' : '41450', 'DEAL_YMD' : YMD}
response = requests.get(url, params=params)
soup = BS(response.text, 'xml')
if len(soup.find_all('item')) == 0:
break
for item in soup.find_all('item'):
record = []
record.append(item.find('거래금액').text)
record.append(item.find('아파트').text)
record.append(item.find('년').text)
record.append(item.find('월').text)
record.append(item.find('전용면적').text)
data.append(record)
pageNo += 1
if month == 12:
year += 1
month = 1
else:
month += 1
data = pd.DataFrame(data, columns = ["가격", "아파트", "연도", "월", "전용면적"])
data['가격'] = data['가격'].str.lstrip().str.replace(',', '').astype(int)
data[['연도', '월']] = data[['연도', '월']].astype(int)
data['전용면적'] = data['전용면적'].astype(float)로직은 간단합니다. year가 2022이고 month가 10이면 빠져나오는 while문을 만들고 맨 아래에서 month를 1씩 증가시키는 것입니다. 다만 month가 12면 다음 month는 13이 아니라 1이라는 점을 고려해서 if - else를 썼습니다.
여기서 사용한 전체 코드는 아래에서 다운로드받을 수 있습니다.

도움이 되었다면 공감버튼 클릭부탁드립니다!
정리하고 싶은 공공데이터가 있다면 댓글이나 이메일(gils_lab@naver.com)으로 연락부탁드립니다.
'데이터사이언스 > 공공데이터' 카테고리의 다른 글
| 지역별 학교 데이터 (3) | 2022.11.26 |
|---|
