
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 코딩테스트
- 사이킷런
- 주요 파라미터
- 데이터사이언티스트
- 경력 기술서
- 파이썬
- 데이터분석
- 주가데이터
- 주식데이터
- 데이터 사이언스
- 공공데이터
- 자기소개서
- 커리어전환
- 경력기술서 첨삭
- 판다스
- 대학원
- 하이퍼 파라미터 튜닝
- 랜덤포레스트
- 데이터사이언스
- 과제전형
- AutoML
- 데이터 사이언티스트
- pandas
- 데이터 분석
- 하이퍼 파라미터
- 퀀트 투자 책
- 머신러닝
- 이력서 첨삭
- sklearn
- 퀀트
- Today
- Total
GIL's LAB
list comprehension의 효율성 검증 실험 본문
본 포스팅에서는 파이썬의 list comprehension이 얼마나 효율적인지를 간단한 실험을 통해 알아보겠습니다.
실험은 Jupyter notebook의 %%timeit 매직키워드를 사용하여 실행 시간을 측정해서 비교하는 방식으로 수행하겠습니다.
1. 조건과 함수를 사용하지 않았을 때의 비교
리스트에 속한 모든 요소를 그대로 가져오는 케이스에 대해 실험을 해보겠습니다.
먼저 실험에 사용할 리스트를 다음과 같이 정의해줍니다.
L = list(range(100))이제 세 가지의 방법으로 L의 요소를 갖는 리스트 L1, L2, L3를 만들어보겠습니다.
방법 1. Append를 사용하는 경우
%%timeit
L1 = []
for v in L:
L1.append(v)[실행 결과]
9.9 µs ± 678 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
방법 2. 요소 변경을 하는 경우
%%timeit
L2 = [0] * len(L)
for i, v in enumerate(L):
L2[i] = v[실행 결과]
10.1 µs ± 694 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
방법 3. List comprehension을 사용하는 경우
%%timeit
L3 = [v for v in L][실행 결과]
4.69 µs ± 181 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
1차 실험 결과 정리
각 방법을 실행했을 때 소요된 시간의 평균과 표준편차를 사용하여 정규 분포로 도식화하면 다음과 같습니다.

육안으로 보더라도 방법 1과 2보다 3이 통계적으로 유의한 차이가 있을정도로 빠르며, 그 차이는 2배에 가깝다는 것을 알 수 있습니다.
2. if를 사용했을 때의 성능 비교
리스트에 속한 요소 가운데 특정 조건을 만족하는 요소만 가져오는 케이스에 대해 실험을 해보겠습니다.
먼저 실험에 사용할 리스트를 다음과 같이 정의해줍니다.
L = list(range(100))이제 세 가지의 방법으로 L의 요소 가운데 짝수 요소만 갖는 리스트 L1, L2, L3를 만들어보겠습니다.
방법 1. Append를 사용하는 경우
%%timeit
L1 = []
for v in L:
if v % 2 == 0:
L1.append(v)[실행 결과]
13.5 µs ± 342 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)방법 2. List comprehension을 사용하는 경우
%%timeit
L2 = [v for v in L if v % 2 == 0][실행 결과]
10.8 µs ± 219 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
2차 실험 결과 정리
각 방법을 실행했을 때 소요된 시간의 평균과 표준편차를 사용하여 정규 분포로 도식화하면 다음과 같습니다.
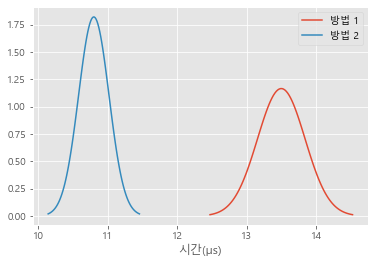
육안으로 보더라도 방법 2의 실행 속도가 방법 1보다 빠르며 그 차이는 통계적으로 유의한 차이가 있어 보입니다. 다만 그 차이가 몇 배에 달하지는 않습니다.
3. 함수를 사용했을 때의 성능 비교
리스트에 속한 요소에 대해 특정 함수를 적용한 요소를 가져오는 케이스에 대해 실험을 해보겠습니다.
먼저 실험에 사용할 리스트와 함수를 다음과 같이 정의해줍니다.
L = list(range(100))
f = lambda x:x**2
이제 세 가지의 방법으로 L의 요소에 일괄적으로 함수 f를 적용해보겠습니다.
방법 1. Append를 사용하는 경우
%%timeit
L1 = []
for v in L:
L1.append(f(v))[실행 결과]
51 µs ± 2.37 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
방법 2. map을 사용하는 경우
%%timeit
L2 = list(map(f, L))[실행 결과]
38.6 µs ± 1.21 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
방법 3. List comprehension을 사용하는 경우
%%timeit
L3 = [f(v) for v in L][실행 결과]
44.2 µs ± 1.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
3차 실험 결과 정리
각 방법을 실행했을 때 소요된 시간의 평균과 표준편차를 사용하여 정규 분포로 도식화하면 다음과 같습니다.

이번에는 겹치는 구간이 발생했습니다. 그렇지만 통계적으로 유의한 차이는 있어보입니다. 단순한 함수를 적용하는 것이라면 list comprehension보다는 map을 사용하는 것이 더 효율적인듯합니다.
4. 함수와 if-else 조건을 사용했을 때의 성능 비교
리스트에 속한 요소 가운데 만족하는 조건에 따라 다른 함수를 적용하는 케이스에 대해 실험해보겠습니다.
먼저 실험에 사용할 리스트와 함수를 다음과 같이 정의해줍니다.
L = list(range(100))
f1 = lambda x:x*2
f2 = lambda x:x*2 - 1함수 f1은 L의 요소 가운데 홀수인 요소에 대해 적용할 것이며, f2는 짝수 요소에 대해 적용할 것입니다.
방법 1. Append를 사용하는 경우
%%timeit
L1 = []
for v in L:
if v % 2 == 1:
L1.append(f1(v))
else:
L1.append(f2(v))
[실행 결과]
37.8 µs ± 3.42 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
방법 2. List comprehension을 사용하는 경우
%%timeit
L2 = [f1(v) if v % 2 == 1 else f2(v) for v in L]
4차 실험 결과 정리
각 방법을 실행했을 때 소요된 시간의 평균과 표준편차를 사용하여 정규 분포로 도식화하면 다음과 같습니다.
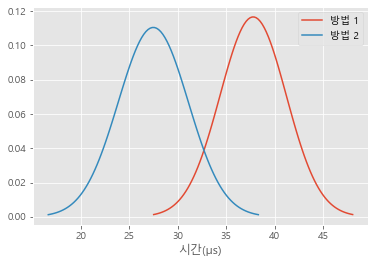
이번에도 겹치는 구간이 발생했지만 통계적으로 방법 2가 더 빨라보입니다.
나가며
결론적으로는 list comprehension을 사용하는 것이 일반적인 for문을 사용하는 것보다는 효율적입니다. 예외가 있다면 한 리스트의 모든 요소에 대해 일괄적으로 함수를 적용하는 경우에는 map을 쓰는 것이 더 효율적이라는 것입니다.
'파이썬 > 파이썬 활용 팁' 카테고리의 다른 글
| 문자열 분리하기 (0) | 2023.08.09 |
|---|---|
| str.findall: 특정 단어가 포함되었는지를 확인 (0) | 2022.12.28 |
| 파이썬 인스턴스 (AI 모델 포함) 크기 측정 방법 (0) | 2022.01.14 |
| 모듈에서 파일 불러오기: pkg_resources.resource_filename (0) | 2021.12.16 |