table 요소에서 행은 tr 요소에 정리되어 있다 (물론 크롬의 검사를 이용해도 알 수 있다).
첫 행이 어떻게 구성되어 있는지를 먼저 살펴보자. 첫 행은 제목 행이며, 각 셀들이 th에 있음을 알 수 있다.
제목은 우리가 직접 정의를 할 것이기 때문에, 두 번째 행을 살펴보자.
tr은 여러 개의 td 셀로 구성되어 있으며, 각 td에서 텍스트에 해당하는 부분만 가져오면 될 것이라는 판단이 된다.
예를 들어, 두 번째 행의 첫 번째와 두 번째 요소를 확인해보자.
아래 코드를 해석해보면, table에서 1번째 위치의 tr의 0번째 위치의 td의 텍스트와 1번째 위치의 텍스트를 반환한 것이다.
문제는 제목이 조금 더럽게 되어 있다.
그 이유는 아래와 같이 제목이 짤려있어서 그렇다.
다른 행에서도 같은 현상이 발생하는지를 확인해보자.
제목에서 종목코드와 종목명을 추출한 뒤, 노이즈를 제거하는 방식을 채택하기 위한 함수를 만들어, 해당 문제를 해결하자. 먼저 종목코드와 종목명을 가져오기 위해, FinanceDataReader를 사용하여 다음과 같이 가져온다.
import FinanceDataReader as fdr
stocks = fdr.StockListing('KRX') # 코스피, 코스닥, 코넥스 전체
stocks.head()
그리고 아래와 같은 함수를 작성하자.
만약 종목명과 코드가 없는 제목이면 [None]을 리턴하는데, 이는 추후에 데이터에 추가하지 않기 위한 트릭이다.
stocks['Symbol'] = stocks['Symbol'].astype(str)
def remove_noise_and_split_title(title):
in_code = ''
in_name = ''
for code, name in stocks[['Symbol', 'Name']].values:
if code in title and name in title:
in_code = code
in_name = name
# 한글, 영어, 숫자 외 노이즈 제거
clean_title = re.sub('[^A-Za-z0-9가-힣]', ' ', title)
# 기업명 코드 수정
clean_title = clean_title.replace(in_code, ' ')
clean_title = clean_title.replace(in_name, ' ')
while ' ' * 2 in clean_title:
clean_title = clean_title.replace(' ' * 2, ' ')
if in_name == '': # 기업명이 없는 제목이라면, 데이터에 추가하지 않음
return [None]
else:
return [in_name, in_code, clean_title]
이제 각 행과 셀을 순회하면서 값을 저장하자.
참고로 표는 작성일, 제목, 적정가격, 투자의견, 작성자, 제공출처 순으로 되어 있으니, 6개의 셀만 순회하고 1번째 셀에서 방금 만든 함수를 사용하도록 하자.
data = []
for tr in table.find_all("tr")[1:]: # 1번째 행부터 순회
record = []
try: # 종목코드가 없는 경우에는 오류가 발생해서 try except 구문으로 넘김
for i, td in enumerate(tr.find_all("td")[:6]): # 6번째 셀까지 순회
if i == 1:
record += remove_noise_title(td.text) # remove_noise_title의 출력과 이어 붙임
elif i == 3: # 노이즈가 껴있는 세번째 셀만 따로 처리
record.append(td.text.replace(" ", "").replace("\r","").replace("\n",""))
else: # 1번째 셀이 아니면:
record.append(td.text) # 셀의 텍스트 값 그대로 입력
data.append(record)
except:
pass
여기서 평가 의견인 3번째 셀에는 이상한 값이 많이 껴서 따로 노이즈를 처리하였다.
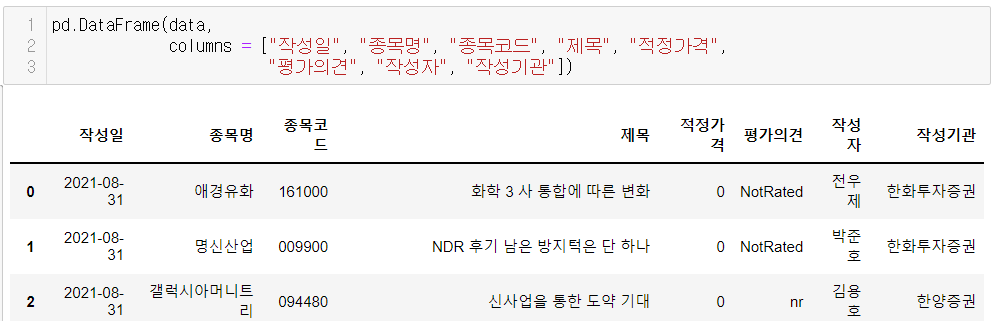
이제 data를 데이터프레임으로 만들어 보자.
전체 페이지에 대한 크롤링
이제 위에서 소개한 코드를 종합하여 전체 페이지를 크롤링해보자.
전체 페이지 개수는 4283개임을 확인했다.
완성된 소스 코드는 다음과 같다.
사실 위의 코드를 이어붙인 것이라서 특별히 설명할 부분이 없다.
기본 url 구조를 정의하고, 거기에 페이지 번호를 바꿔가면서 데이터를 가져왔다는것정도...??
그리고 연결이 아예 끊어지면 15분 쉬었다가 재시도하도록 while 구문을 넣었단거 정도?
base_url = "http://consensus.hankyung.com/apps.analysis/analysis.list?&sdate=2016-09-01&edate=2021-08-31&report_type=CO&order_type=&now_page={}"
data = []
for page_no in range(1, 4284):
while True:
try:
url = base_url.format(page_no)
html = requests.get(url, headers={'User-Agent':'Gils'}).content
soup = BeautifulSoup(html, 'lxml')
print("{}/{}".format(page_no, 4284))
break
except:
time.sleep(15 * 60)
table = soup.find("div", {"class":"table_style01"}).find('table')
for tr in table.find_all("tr")[1:]: # 1번째 행부터 순회
record = []
for i, td in enumerate(tr.find_all("td")[:6]): # 6번째 셀까지 순회
if i == 1:
record += remove_noise_and_split_title(td.text) # remove_noise_title의 출력과 이어 붙임
elif i == 3: # 노이즈가 껴있는 세번째 셀만 따로 처리
record.append(td.text.replace(" ", "").replace("\r","").replace("\n",""))
else: # 1번째 셀이 아니면:
record.append(td.text) # 셀의 텍스트 값 그대로 입력
if None not in record: # 레코드에 None이 없으면
data.append(record)
time.sleep(1) # 연결 끊김 방지를 위해, 1초씩 재움
data = pd.DataFrame(data, columns = ["작성일", "종목명", "종목코드", "제목", "적정가격", "평가의견", "작성자", "작성기관"])
data.to_csv("기업리포트_요약.csv", index = False, encoding = "cp949")