데이터 사이언티스트가 되기 위한 적절한 공부 방법
이번 포스팅에서는 데이터 사이언티스트를 희망하는 사람이 어떤 방식으로 공부해야 하는지에 대해 알아보겠습니다.
한 도메인의 분석을 주로하는 머신러닝 엔지니어(예: 비전, 자연어, 추천 엔지니어 등)에게는 적합한 내용이 아닐 수 있습니다. 또한, 어디까지나 지극히 주관적인 의견이며, 저와 같이 고객의 요청에 따라 만들어지는 프로젝트 단위로 일을 하는 혹은 일을 하게 될 분에게 도움이 될 것입니다.
무엇을 공부해야 하나?
당연히도 데이터 사이언티스트로 취업하기 위해 필요한 지식이나 스킬을 익혀야 합니다.
이 지식이나 스킬에 포함되는 내용을 간략히 정리하면 아래와 같을 것이며 개인적으로 생각하기에 중요한 것을 위에 배치했습니다.
- 머신러닝 / 딥러닝 알고리즘
- 확률 및 통계
- 파이썬 (R)
- 최적화
- SQL
- 하둡, 리눅스 등
개인적으로는 SQL은 기본 문법만 알면 되고, 하둡과 리눅스는 입사해서 익혀도 된다고 생각합니다.
어차피 직접 DB를 구축해서 사용해보는 것 아니라면 사용 자체가 익숙해지기도 어렵고, 실전 경험이랑도 거리가 있게 되니까요.
공부를 위한 마인드셋 (feat. 손으로 모델 학습해보신분?)
일단 가장 버려야 할 마인드는 "입사 전에 데이터사이언티스트에게 필요한 모든 지식을 깊이 있게 공부한다"입니다.
현재까지 나와있는 내용을 다 이해하는 것도 불가능할 뿐더러, 공부하는 속도보다 새로운게 나오는 속도가 훨씬 빠른 분야이기 때문입니다.
그래서 제가 추천하는 기본 마인드는 다음과 같습니다.
기본적인 것은 알고 있으되, 필요하면 구글링해서 다시 공부한다.
저도 박사과정때 많은 분야를 공부했지만 실제로 지금 당장 자세히 설명할 수 있는건 많지 않습니다.
학부때야 시험을 위해서 외웠지만, 대학원 과정과 회사 생활에서는 기본이 오픈북이니까요.
예를 들어서, 저는 서포트 벡터 머신을 강의에서 많이 설명해봤지만, ML 패키지를 사용하지 않고 스크래치부터 구현하라고 하면 많이 애를 먹을 것입니다. 그렇지만 기본적인 구조를 알고 있기 때문에 구글링을 해가면서 어떻게든 만들 수 있을 것 같습니다.
이 마인드가 왜 적절한지 생각해보겠습니다. 먼저, 프로젝트마다 필요한 지식의 종류와 깊이가 크게 다릅니다. 특히 깊이를 살펴보면 어찌되었건 누군가 만들어둔 코드를 활용하는 경우가 많기 때문에 내가 그 내용을 완벽히 알고 있을 필요는 없습니다. 우리가 실제 파이썬으로 모델을 학습할 때는 몇 줄의 코드면 충분한 것처럼요.
수업에서 하는 것을 제외하면 손으로 하나하나 구현하는 경우는 특수한 상황을 제외하면 최소한 실무에서는 없습니다.
알고리즘의 특성을 공부하자.
그렇지만 알고리즘의 특성 등은 반드시 알고 있어야 합니다.
그래야 문제가 주어졌을 때, 어느 알고리즘이 적합한지를 판단할 수 있고 또 어떻게 이 알고리즘을 활용할지를 알 수 있습니다.
가령 k-최근접 이웃 모델은 거리 척도로 맨하탄 거리나 유클리디안 거리를 사용했을 때 변수 스케일에 크게 영향을 받습니다. 그렇기 때문에 통상적으로 스케일링과 특징 선택을 했을 때 성능 향상을 기대할 수 있는 모델입니다.
왜 그런지 생각해보면 맨하탄 거리나 유클리디안 거리 자체가 변수의 스케일에 영향을 크게 받기 때문에 그렇습니다.
가령, 두 벡터 a = (0, 1억), b = (1, 2억)이 있다고 해보겠습니다. 각 차원과 대응되는 변수는 x1, x2로 x1은 0~1 스케일, x2는 1억 ~ 10억 스케일이라고 해보겠습니다.
이 경우에 두 벡터 간 맨하탄 거리는 |1-0| + |2억 - 1억|으로 정의됩니다. 여기서 x2란 변수의 차이(1억)가 x1의 차이(1)를 의미없게 만들었습니다. 게다가 x1은 0과 1사이의 스케일이어서 a는 0이고 b는 1이라면 양 극단에 있던 것인데도 말이죠.
이는 맨하탄 거리의 공식을 보면 사실 유추할 수 있는 내용입니다.
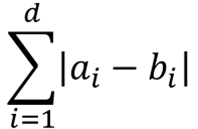
제가 말하고 싶은 것은 위의 공식을 외우는게 중요한게 아니고, 위의 공식처럼 생겼기 때문에 어떤 특성이 생기는지를 이해하는 것입니다.
이런식으로 어떤 특성이 있을 것이다를 유추하면서 공부하는게 실무에서는 크게 도움이 됩니다.
처음에는 외우는 것보다 이게 더 어렵게 느껴지겠지만, 계속하다보면 눈치가 더 빠르게 늡니다.
그리고 너무 어렵다싶으면 논문이나 블로그 등을 참고해서 이 모델의 특성은 무엇이 있는지, 그 특성으로 인해 어떻게 데이터를 전처리하고 하이퍼 파라미터 튜닝을 해야 하는지 등을 익혀두면 좋겠습니다.
나가며
정리하면 데이터 사이언티스트에게 필요한 지식의 범위가 굉장히 넓고 생성되는 속도도 빨라서 모든 것을 공부하고 취업한다고 생각하지 말고, 실무에서 활용할 수 있는 지식, 즉, 모델의 특성은 어떠한지, 혹은 어떤 아이디어에 기반한 모델인지 등을 중심으로 공부하기를 바랍니다.
데이터 분야 취업 컨설팅/자기소개서 첨삭/이력서 첨삭은 아래 링크로!
데이터 사이언스 박사가 데이터 분야 취업, 진학을 도와 | 50000원부터 시작 가능한 총 평점 5점의
18개 총 작업 개수 완료한 총 평점 5점인 데이터사이언스박사의 문서·글쓰기, 이력서 교정 서비스를 18개의 리뷰와 함께 확인해 보세요. 문서·글쓰기, 이력서 교정 제공 등 50000원부터 시작 가능
kmong.com